Avevo scritto un frammento di codice in PHP. Dato un input, impiegava 20 secondi a restituire l'output. Ho aggiunto 10 righe, ed ora ce ne mette un paio.
Il protagonista della storia e' GASdotto (il gestionale per Gruppi di Acquisto qualche volta menzionato su questo blog), applicazione che ho imbastito seguendo il piu' possibile la regola secondo cui e' meglio del codice compatto e generico anziche' una gestione manuale (ed ottimizzata) di tutti i casi possibili. Con risultati evidentemente non sempre gratificanti.
Tutta la componente server del programma (cosiccome del resto anche la parte client, in Java) e' fondata su una classe elementare che funge da astrazione per tutte le altre: le sottoclassi di questa definiscono solo quali sono le variabili che contiene (tipo: lo User ha un firstname che e' una stringa, un lastlogin che e' una data...), e tutta la parte di ricostruzione dell'oggetto dal database, serializzazione e deserializzazione JSON, salvataggio, aggiornamento e cancellazione e' implementata una volta sola nella classe di partenza. Tale meccanismo copre anche il caso in cui un oggetto contenga un array di oggetti di altro tipo, i quali sono mappati sul database seguendo una logica predefinita e dunque uguale per tutti e riportata in forma di codice una volta sola. Insomma: una architettura che mi ha permesso di realizzare pressoche' tutta la parte server del software in 2000 righe di PHP (stando alle attuali statistiche su Ohloh), ed in cui posso aggiungere nuovi elementi completi di tutte le funzionalita' con una manciata di altre righe.
Fin qui tutto bello. Il brutto viene mettendo insieme molti oggetti che contengono a loro volta molti oggetti.
Dato un numero di ordini, i quali contengono un numero di prodotti ordinati, ognuno dei quali fa riferimento ad un prodotto disponibile nell'ordine, ognuno dei quali fa riferimento al fornitore che lo distribuisce, e' evidente (soprattutto col senno di poi...) che la quantita' di componenti coinvolti nella semplice richiesta di avere tutte le merci che sono state richieste dai membri del Gruppo di Acquisto e' elevata. Ed attenendosi al primo modello operativo di riferimento ognuno di essi deve essere ripescato dal database e ricondotto ad un oggetto. Anche se e' gia' stato prelevato all'interno dell'elaborazione della stessa richiesta.
Non voglio neanche sapere quante query venivano eseguite in tal frangente, ma non appena mi sono accorto del problema ho applicato in pochi secondi una soluzione basata su un banale array associativo usato a mo' di cache temporanea per tener traccia di quanto gia' ottenuto e recuperarlo subito senza ricostruirlo daccapo: certamente non ottimale, ma funzionale.
La morale di questa narrazione e' di non fidarsi sempre ciecamente dei dogmi dell'ingegneria software: astrarre e' un'ottima cosa, soprattutto se si e' pigri, ma, giacche' la perfezione non e' di questo mondo, per quanto raffinato il vostro sistema avra' sempre una falla, dunque tanto vale rassegnarsi e prepararsi da subito a dover applicare un salutare ed ingenuo hack di quando in quando.
Pensieri e parole su HCI, home computing, tecnologie desktop e sul Progetto Lobotomy
domenica 13 dicembre 2009
mercoledì 25 novembre 2009
Il Nome della Cosa
Qualche tempo fa' in Itsme sono passati alcuni ospiti: come sempre abbiamo fatto la nostra presentazione del progetto, come sempre ci sono state domande tecniche e meno tecniche, e tra tutte le osservazioni emerse una in particolare mi ha ispirato il qui presente post. In realta' si tratta di un commento piu' e piu' volte sollevato in merito all'opera in corso, carpito in circostanze piu' o meno ufficiali e che suona come "Itsme e' basato su Linux, ma Linux e' difficile da usare".
Sorvolando sulle obiezioni di natura culturale e pedagogica, per cui un meccanismo complesso come un intero sistema operativo non puo' essere a priori "facile" o "difficile" ma necessariamente richieste un periodo di addestramento ed un disadattamento all'attivita' su altre piattaforme analoghe rendendo di fatto "difficile" tutto quello che non si e' usato fino al giorno prima, cio' che mi perplime e' il pregiudizio di fondo nei confronti di Linux.
Per quanto nel corso delle dimostrazioni Itsme si parli dell'interfaccia che stiamo completamente ri-disegnando e re-implementando per adattarsi alla metafora di riferimento, cosiccome stiamo ri-disegnando e re-implementando gli automatismi di fondo che permettono la configurazione, "Linux e' difficile". Tale assioma e' assunto indipendentemente dalla modalita' grafica con cui il sistema si presenta, degli strumenti di tuning messi a disposizione, dei wizards automatici gia' previsti per sopperire ad eventuali mancanze ed integrare componenti gia' noti nel piano: "Linux e' difficile".
Eppure a me non pare che nessuno si sia mai grattato il capo in modo imbarazzato usando un cellulare Motorola, spedendo richieste a Google, o anche facendo un biglietto della metropolitana qui a Torino. Questo perche' i tre fruitori di cui sopra, e buona parte di tutti gli altri fornitori di hardware e servizi Linux-based, dell'amato sistema operativo utilizzano la tecnologia di base ed hanno personalizzato per conto proprio la parte con cui l'utente interagisce, rendendo piu' o meno "facile" l'uso dell'apparato a seconda del fine predestinato. Ne' piu' ne' meno di quanto fatto da Apple con MacOS X, partendo da una base BSD (che di per se' puo' essere considerato ancor piu' ostico che Linux stesso) e costruendoci sopra il proprio stack applicativo, rinomato come il piu' user-friendly sul mercato: sarebbe sensato affermare che MacOS e' "difficile" da usare perche' ha nel kernel lo stesso scheduler di BSD, laddove l'utilizzatore non sospetta neppure l'esistenza di un'arnese chiamato "scheduler"?
E se anche fosse vero che, diciamo, una Ubuntu e' meno usabile di un Windows (argomento discutibile ed opinabile), e' altrettanto vero che godendo di una netta separazione tra i layer operativi Linux si presta molto di piu' ad una drastica personalizzazione dell'insieme e da esso e' molto piu' facile cavare qualcosa di realmente nuovo e pratico mantendendo intonse le porzioni di basso livello (gestione dei devices, librerie software, toolkits grafici, alcuni applicativi) e stravolgendo il resto, a propria discrezione e secondo la propria necessita'. Stando alla mia esperienza sinora ho lavorato su un apparato embedded per telecomunicazioni ed una workstation desktop, e su entrambi il software di basso livello era lo stesso, ovvero un kernel e qualche libreria.
Stat Linux pristina nomine, nomina nuda tenemus.
Sorvolando sulle obiezioni di natura culturale e pedagogica, per cui un meccanismo complesso come un intero sistema operativo non puo' essere a priori "facile" o "difficile" ma necessariamente richieste un periodo di addestramento ed un disadattamento all'attivita' su altre piattaforme analoghe rendendo di fatto "difficile" tutto quello che non si e' usato fino al giorno prima, cio' che mi perplime e' il pregiudizio di fondo nei confronti di Linux.
Per quanto nel corso delle dimostrazioni Itsme si parli dell'interfaccia che stiamo completamente ri-disegnando e re-implementando per adattarsi alla metafora di riferimento, cosiccome stiamo ri-disegnando e re-implementando gli automatismi di fondo che permettono la configurazione, "Linux e' difficile". Tale assioma e' assunto indipendentemente dalla modalita' grafica con cui il sistema si presenta, degli strumenti di tuning messi a disposizione, dei wizards automatici gia' previsti per sopperire ad eventuali mancanze ed integrare componenti gia' noti nel piano: "Linux e' difficile".
Eppure a me non pare che nessuno si sia mai grattato il capo in modo imbarazzato usando un cellulare Motorola, spedendo richieste a Google, o anche facendo un biglietto della metropolitana qui a Torino. Questo perche' i tre fruitori di cui sopra, e buona parte di tutti gli altri fornitori di hardware e servizi Linux-based, dell'amato sistema operativo utilizzano la tecnologia di base ed hanno personalizzato per conto proprio la parte con cui l'utente interagisce, rendendo piu' o meno "facile" l'uso dell'apparato a seconda del fine predestinato. Ne' piu' ne' meno di quanto fatto da Apple con MacOS X, partendo da una base BSD (che di per se' puo' essere considerato ancor piu' ostico che Linux stesso) e costruendoci sopra il proprio stack applicativo, rinomato come il piu' user-friendly sul mercato: sarebbe sensato affermare che MacOS e' "difficile" da usare perche' ha nel kernel lo stesso scheduler di BSD, laddove l'utilizzatore non sospetta neppure l'esistenza di un'arnese chiamato "scheduler"?
E se anche fosse vero che, diciamo, una Ubuntu e' meno usabile di un Windows (argomento discutibile ed opinabile), e' altrettanto vero che godendo di una netta separazione tra i layer operativi Linux si presta molto di piu' ad una drastica personalizzazione dell'insieme e da esso e' molto piu' facile cavare qualcosa di realmente nuovo e pratico mantendendo intonse le porzioni di basso livello (gestione dei devices, librerie software, toolkits grafici, alcuni applicativi) e stravolgendo il resto, a propria discrezione e secondo la propria necessita'. Stando alla mia esperienza sinora ho lavorato su un apparato embedded per telecomunicazioni ed una workstation desktop, e su entrambi il software di basso livello era lo stesso, ovvero un kernel e qualche libreria.
Stat Linux pristina nomine, nomina nuda tenemus.
lunedì 19 ottobre 2009
Hands on Google Wave
In merito a Google Wave ho gia' fatto un commento (negativo) ai tempi del suo annuncio e della pubblicazione del lungo video di presentazione. Ora che grazie ad un amico ho ottenuto un invito ed ho potuto provarlo con mano, aggiorno il commento e lo rendo ancora piu' negativo.
L'intera Internet, o quantomeno coloro che gia' hanno ottenuto il modo per fare qualche prova col suddetto prodotto, si chiede a cosa serva: non e' uno tool di instant messaging perche' i messaggi sono disposti in threads, non e' un forum perche' e' realtime, non e' uno strumento di editing collaborativo perche' ha una struttura predefinita. Insomma non e' nulla di gia' noto, ma al tempo stesso prende tutti i difetti dei canali menzionati sopra: e' lento e macchinoso come un forum e per pubblicare un nuovo messaggio c'e' da cliccare qua e la', essendo realtime non e' banale tenere una conversazione con qualcuno in quanto viene spontaneo rispondere prima che l'altro abbia finito di esprimersi completamente, ed ha un modello gerarchico dunque non puo' essere usato per scopi "generici" come un foglio su Google Docs.
A seguito del test drive, i miei dubbi diventano certezze: questa baracca non serve a niente. In molti si scervellano per cercare di dargli un significato, una dimensione, un ruolo, ma credo che sforzarsi di assegnare un titolo ad un prodotto solo perche' proviene da una fonte (piu' o meno) amata come Google sia un eccesso. Ammetto di non aver letto proprio tutte le recensioni quotidianamente proposte, ma tra tutte quella che maggiormente mi ha colpito e' questa qui: l'autore sostiene che l'utente piu' indicato per Wave sia quello che in genere e' il peggior consumatore di tecnologia informatica, ovvero l'utente business/corporate, quello che ancora non ha scoperto l'IM o gli altri ammenicoli collaborativi online e a tutt'oggi scambia coi suoi pari via mail gli stessi documenti centinaia di volte per apportare modifiche e correzioni. Ma io mi domando e chiedo: se questo "utente tipo" e' talmente radicato alle sue abitudini da non aver manco mai pensato ad aprirsi il piu' stupido account MSN (e figuriamoci un account su Zoho), come si spera che da un giorno all'altro inizi ad usare Wave???
Da notare poi che codeste mie critiche si limitano al puro scopo funzionale dell'applicazione, in quanto se dovessi puntualizzare anche sul versante tecnico non finirei il post entro oggi: l'interfaccia e' ridondante, non fa niente eppure ci sono troppi tasti e pulsanti e icone (quasi che lo scopo fosse quello di dimostrare la fighettosita' di una applicazione realizzata con GWT anziche' impostare un frontend chiaro ed intuitivo), l'organizzazione dei contenuti e' abbozzata, innumerevoli i difettucci legati alle notifiche ed all'allineamento dei messaggi nonche' le incoerenze dell'interazione. Cui si sommano le limitazioni contingenti di ogni applicazione web, che essendo vincolate all'interno del browser non hanno modo di interagire col window manager e dunque portare all'attenzione dell'utente notifiche e segnalazioni.
Se mai Wave avra' un qualche riscontro e sara' usato da qualcuno il merito sara' certamente piu' della campagna di marketing e dell'hype sorto intorno a codesto oggetto che non per un reale valore operativo. Chi ancora non ha un invito non se ne disperi troppo, non si sta perdendo niente e puo' tranquillamente attendere l'apertura del servizio a tutti.
Anche oggi, l'Internet resta la stessa.
L'intera Internet, o quantomeno coloro che gia' hanno ottenuto il modo per fare qualche prova col suddetto prodotto, si chiede a cosa serva: non e' uno tool di instant messaging perche' i messaggi sono disposti in threads, non e' un forum perche' e' realtime, non e' uno strumento di editing collaborativo perche' ha una struttura predefinita. Insomma non e' nulla di gia' noto, ma al tempo stesso prende tutti i difetti dei canali menzionati sopra: e' lento e macchinoso come un forum e per pubblicare un nuovo messaggio c'e' da cliccare qua e la', essendo realtime non e' banale tenere una conversazione con qualcuno in quanto viene spontaneo rispondere prima che l'altro abbia finito di esprimersi completamente, ed ha un modello gerarchico dunque non puo' essere usato per scopi "generici" come un foglio su Google Docs.
A seguito del test drive, i miei dubbi diventano certezze: questa baracca non serve a niente. In molti si scervellano per cercare di dargli un significato, una dimensione, un ruolo, ma credo che sforzarsi di assegnare un titolo ad un prodotto solo perche' proviene da una fonte (piu' o meno) amata come Google sia un eccesso. Ammetto di non aver letto proprio tutte le recensioni quotidianamente proposte, ma tra tutte quella che maggiormente mi ha colpito e' questa qui: l'autore sostiene che l'utente piu' indicato per Wave sia quello che in genere e' il peggior consumatore di tecnologia informatica, ovvero l'utente business/corporate, quello che ancora non ha scoperto l'IM o gli altri ammenicoli collaborativi online e a tutt'oggi scambia coi suoi pari via mail gli stessi documenti centinaia di volte per apportare modifiche e correzioni. Ma io mi domando e chiedo: se questo "utente tipo" e' talmente radicato alle sue abitudini da non aver manco mai pensato ad aprirsi il piu' stupido account MSN (e figuriamoci un account su Zoho), come si spera che da un giorno all'altro inizi ad usare Wave???
Da notare poi che codeste mie critiche si limitano al puro scopo funzionale dell'applicazione, in quanto se dovessi puntualizzare anche sul versante tecnico non finirei il post entro oggi: l'interfaccia e' ridondante, non fa niente eppure ci sono troppi tasti e pulsanti e icone (quasi che lo scopo fosse quello di dimostrare la fighettosita' di una applicazione realizzata con GWT anziche' impostare un frontend chiaro ed intuitivo), l'organizzazione dei contenuti e' abbozzata, innumerevoli i difettucci legati alle notifiche ed all'allineamento dei messaggi nonche' le incoerenze dell'interazione. Cui si sommano le limitazioni contingenti di ogni applicazione web, che essendo vincolate all'interno del browser non hanno modo di interagire col window manager e dunque portare all'attenzione dell'utente notifiche e segnalazioni.
Se mai Wave avra' un qualche riscontro e sara' usato da qualcuno il merito sara' certamente piu' della campagna di marketing e dell'hype sorto intorno a codesto oggetto che non per un reale valore operativo. Chi ancora non ha un invito non se ne disperi troppo, non si sta perdendo niente e puo' tranquillamente attendere l'apertura del servizio a tutti.
Anche oggi, l'Internet resta la stessa.
martedì 13 ottobre 2009
Vapore Multitouch
Pubblicato da
Roberto -MadBob- Guido
alle
19:26
0
commenti
Etichette:
devices,
future,
mobile,
news,
touch
Risale a qualche settimana fa' il meme del tablet targato Microsoft, chiamato Courier. Molti hanno detto la propria, io (sebbene con un poco di ritardo) dico la mia: secondo me, e' una bufala.
Le motivazioni di un gesto di tal fatta sono scontate: rosicchiare un poco della attenzione e della visibilita' offerte sull'argomento "tablet" a seguito dei reiterati rumors in merito ad un nuovo prodotto Apple, destinato (vuoi per tendenza modaiola, vuoi per effettivo grado innovativo tradizionalmente iniettato sul mercato dall'azienda di Cupertino) a ridare nuova vita ad un settore esistente da anni ma che non ha mai scalfito l'interesse del grande pubblico consumer.
Ma la mia affermazione non e' fondata solo sulla pura intuizione (oltretutto neanche tanto originale) e sul pregiudizio nei confronti di Microsoft, ma su riflessioni indotte dalla visione del video di introduzione al suddetto Courier. Osservando quei quattro minuti di filmato, spacciati per tech demo dell'imminente prodotto, a me sembra abbastanza evidente che il modello di interazione e' cosi' artefatto da non poter essere reale: comportamenti grafici diversi, ovviamente sempre i piu' adatti alla regia, si ottengono a seguito delle medesime operazioni dell'utente, ed il pannello giallo che ogni tanto appare (e non ho neanche capito a cosa serva...) sembra dotato di una propria coscienza tanto da apparire solo quando scenicamente opportuno. Per non parlare delle barre in cui si scrive a mano per raggiungere un dato contenuto (bella forza immettere l'URL "afi.com" nel browser, ma come ce lo faccio stare "slashdot.org"?), le tabelline che magicamente vengono estratte e trascinate senza manco sapere qual'e' la porzione di interesse per l'utente, il tratto dello stilo che diventa testo o evidenziatura gialla in modo totalmente arbitrario...
Insomma, piu' che un prototipo di interazione a me sembra un film di azione, in cui i cattivi sparano dozzine di proiettili senza mai neppure ferire i buoni e l'eroe fa di ogni colpo un centro: molto divertente da vedere, ma non credibile. Poi, per la carita', qualcosa di interessante lo si trova anche, come il concetto di piazzare i contenuti di traverso tra le due pagine per, all'atto pratico, metterlo in clipboard, ma cio' non toglie nulla alla mia incredulita' di vedere davvero questo arnese sugli scaffali nei prossimi mesi.
Al contrario, sono ben contento di vedere che una fascia di prodotti su cui da tempo ripongo la mia attenzione stia in qualche modo uscendo dalla nicchia in cui e' stata relegata per anni ed i grandi produttori nel bene e nel male procedano con sperimentazioni e ricerche: continuo a ritenere l'idea del tablet una direzione quasi obbligata per gli sviluppi tecnologici futuri, in virtu' del rapporto dati esposti / superficie ingombrante di cui tali dispositivi godono, e nella speranza di poter presto trovare un degno sostituto al mio Acer C310 (quattro anni fa' il miglior convertibile che ho trovato sulla piazza, e da allora rimasto tale a causa della scarsita' di alternative) continuo a seguire gli sviluppi.
Le motivazioni di un gesto di tal fatta sono scontate: rosicchiare un poco della attenzione e della visibilita' offerte sull'argomento "tablet" a seguito dei reiterati rumors in merito ad un nuovo prodotto Apple, destinato (vuoi per tendenza modaiola, vuoi per effettivo grado innovativo tradizionalmente iniettato sul mercato dall'azienda di Cupertino) a ridare nuova vita ad un settore esistente da anni ma che non ha mai scalfito l'interesse del grande pubblico consumer.
Ma la mia affermazione non e' fondata solo sulla pura intuizione (oltretutto neanche tanto originale) e sul pregiudizio nei confronti di Microsoft, ma su riflessioni indotte dalla visione del video di introduzione al suddetto Courier. Osservando quei quattro minuti di filmato, spacciati per tech demo dell'imminente prodotto, a me sembra abbastanza evidente che il modello di interazione e' cosi' artefatto da non poter essere reale: comportamenti grafici diversi, ovviamente sempre i piu' adatti alla regia, si ottengono a seguito delle medesime operazioni dell'utente, ed il pannello giallo che ogni tanto appare (e non ho neanche capito a cosa serva...) sembra dotato di una propria coscienza tanto da apparire solo quando scenicamente opportuno. Per non parlare delle barre in cui si scrive a mano per raggiungere un dato contenuto (bella forza immettere l'URL "afi.com" nel browser, ma come ce lo faccio stare "slashdot.org"?), le tabelline che magicamente vengono estratte e trascinate senza manco sapere qual'e' la porzione di interesse per l'utente, il tratto dello stilo che diventa testo o evidenziatura gialla in modo totalmente arbitrario...
Insomma, piu' che un prototipo di interazione a me sembra un film di azione, in cui i cattivi sparano dozzine di proiettili senza mai neppure ferire i buoni e l'eroe fa di ogni colpo un centro: molto divertente da vedere, ma non credibile. Poi, per la carita', qualcosa di interessante lo si trova anche, come il concetto di piazzare i contenuti di traverso tra le due pagine per, all'atto pratico, metterlo in clipboard, ma cio' non toglie nulla alla mia incredulita' di vedere davvero questo arnese sugli scaffali nei prossimi mesi.
Al contrario, sono ben contento di vedere che una fascia di prodotti su cui da tempo ripongo la mia attenzione stia in qualche modo uscendo dalla nicchia in cui e' stata relegata per anni ed i grandi produttori nel bene e nel male procedano con sperimentazioni e ricerche: continuo a ritenere l'idea del tablet una direzione quasi obbligata per gli sviluppi tecnologici futuri, in virtu' del rapporto dati esposti / superficie ingombrante di cui tali dispositivi godono, e nella speranza di poter presto trovare un degno sostituto al mio Acer C310 (quattro anni fa' il miglior convertibile che ho trovato sulla piazza, e da allora rimasto tale a causa della scarsita' di alternative) continuo a seguire gli sviluppi.
Bronzo
Ed alla fine della fiera al Social Desktop Contest mi sono classificato terzo.
Con libopengdesktop (tra le mie due candidature, quella a minor contenuto innovativo), e dopo l'ExtendedAboutDialog (in effetti molto grazioso) ed il Knowledge Base Widget (quattro righe di C++ in croce, destino vuole scritte da uno di un paesello relativamente vicino a Torino).
Non mi dilungo ulteriormente in commenti, che non possono che essere di parte (esattamente come la giuria del contest, promosso dalla combriccola di KDE e dunque con qualche inevitabile lieve inclinazione...), e soprassedo anche sul fatto che abbiano scritto il mio nome al contrario, prima il cognome e poi il nome; attendo solo di ricevere la gift card da 50 dollari da spendere ancora non so come su Amazon.
Piu' che all'occasione sfumata di ottenere un netbook o un disco da 1TB (rispettivamente, primo e secondo premio della competizione), rifletto sull'immensamente scarso riscontro ottenuto da una iniziativa tutto sommato, come gia' detto, lodevole, mirata a stimolare la produzione di un po' di software in un contesto che merita attenzione da parte della community quale la condivisione di contributi non programmatori al freesoftware. Nonostante la decentemente ampia promozione e risonanza nella pagina dedicata alle candidature appaiono solo nove proposte, di cui almeno due completamente fuori concorso; due di queste sono mie, dunque volenti o nolenti qualcosa avrebbero comunque dovuto assegnarmelo per ragioni statistiche piu' che di merito. Frank Karlitschek, mente dell'attivita' (e proprietario del network di opendesktop.org), con rara maestria dialettica ha prima posticipando la deadline per le consegne ufficialmente adducendo ad una mole di aspiranti partecipanti che non hanno fatto in tempo a completare le rispettive opere (partecipanti i quali, inutile dirlo, non si sono piu' fatti vedere ne' sentire) e poi si e' deciso dopo lungo ritardo a dichiarare concluso il contest, sperticandosi in entusiasmi per l'ottima riuscita del concorso.
Io, che tanto ottimista non sono, mi domando e chiedo il perche' di un cosi' moderato approccio all'opportunita' fornita. Si potevano vincere dei bei premi con uno sforzo limitato, eppure come gia' detto le proposte avanzate sono state ben poche e pressoche' tutte di scarso impatto. La comunita' KDE (cui Social Desktop e tutta la corte di Karlitschek sono strettamente legati) gode di enorme hype e grande coinvolgimento, a volte persino troppo, e non trovo le ragioni di un cosi' netto fallimento.
Il dubbio e la perplessita' si fanno ancora piu' forti adesso che qui in Italia si approssima il Linux Day, apice del lavoro comunitario di promozione del software libero e occasione in cui emergono i piu' disparati propositi (tra cui i miei) per massimizzare il profitto comunicativo verso il grande pubblico: non c'e' bisogno di arguzia per sapere che tra il discutere una idea e realizzarla ce ne corre, e non poco, ma se persino un progetto della popolarita' di opendesktop.org attrae si' ristretta manodopera non c'e' da star sereni per l'avvenire.
Investire nelle nuove leve, su quella schiera di giovini che ad oggi maturano l'interesse al freesoftware solo in virtu' di cubi rotanti e velleitarie filosofie da ostentare nei circoli nerd? Inventare nuove forme di partecipazione, per abbassare la sbarra ed allargare il bacino di contributors? Le possibilita' sono molteplici, forse non tutte valide ma degne di esplorazione. Sta di fatto che l'utenza Linux su desktop si allarga, i numeri sono ancora piccini ma in costante crescita, e la quantita' di apporti non cresce con lo stesso ritmo.
Se un pugno di tecnici altamente specializzati hanno prodotto i risultati oggi sotto gli occhi di tutti, creare e mantenere un ecosistema realmente attivo e partecipativo puo' portarci la' dove nessun PC e' mai giunto prima.
Con libopengdesktop (tra le mie due candidature, quella a minor contenuto innovativo), e dopo l'ExtendedAboutDialog (in effetti molto grazioso) ed il Knowledge Base Widget (quattro righe di C++ in croce, destino vuole scritte da uno di un paesello relativamente vicino a Torino).
Non mi dilungo ulteriormente in commenti, che non possono che essere di parte (esattamente come la giuria del contest, promosso dalla combriccola di KDE e dunque con qualche inevitabile lieve inclinazione...), e soprassedo anche sul fatto che abbiano scritto il mio nome al contrario, prima il cognome e poi il nome; attendo solo di ricevere la gift card da 50 dollari da spendere ancora non so come su Amazon.
Piu' che all'occasione sfumata di ottenere un netbook o un disco da 1TB (rispettivamente, primo e secondo premio della competizione), rifletto sull'immensamente scarso riscontro ottenuto da una iniziativa tutto sommato, come gia' detto, lodevole, mirata a stimolare la produzione di un po' di software in un contesto che merita attenzione da parte della community quale la condivisione di contributi non programmatori al freesoftware. Nonostante la decentemente ampia promozione e risonanza nella pagina dedicata alle candidature appaiono solo nove proposte, di cui almeno due completamente fuori concorso; due di queste sono mie, dunque volenti o nolenti qualcosa avrebbero comunque dovuto assegnarmelo per ragioni statistiche piu' che di merito. Frank Karlitschek, mente dell'attivita' (e proprietario del network di opendesktop.org), con rara maestria dialettica ha prima posticipando la deadline per le consegne ufficialmente adducendo ad una mole di aspiranti partecipanti che non hanno fatto in tempo a completare le rispettive opere (partecipanti i quali, inutile dirlo, non si sono piu' fatti vedere ne' sentire) e poi si e' deciso dopo lungo ritardo a dichiarare concluso il contest, sperticandosi in entusiasmi per l'ottima riuscita del concorso.
Io, che tanto ottimista non sono, mi domando e chiedo il perche' di un cosi' moderato approccio all'opportunita' fornita. Si potevano vincere dei bei premi con uno sforzo limitato, eppure come gia' detto le proposte avanzate sono state ben poche e pressoche' tutte di scarso impatto. La comunita' KDE (cui Social Desktop e tutta la corte di Karlitschek sono strettamente legati) gode di enorme hype e grande coinvolgimento, a volte persino troppo, e non trovo le ragioni di un cosi' netto fallimento.
Il dubbio e la perplessita' si fanno ancora piu' forti adesso che qui in Italia si approssima il Linux Day, apice del lavoro comunitario di promozione del software libero e occasione in cui emergono i piu' disparati propositi (tra cui i miei) per massimizzare il profitto comunicativo verso il grande pubblico: non c'e' bisogno di arguzia per sapere che tra il discutere una idea e realizzarla ce ne corre, e non poco, ma se persino un progetto della popolarita' di opendesktop.org attrae si' ristretta manodopera non c'e' da star sereni per l'avvenire.
Investire nelle nuove leve, su quella schiera di giovini che ad oggi maturano l'interesse al freesoftware solo in virtu' di cubi rotanti e velleitarie filosofie da ostentare nei circoli nerd? Inventare nuove forme di partecipazione, per abbassare la sbarra ed allargare il bacino di contributors? Le possibilita' sono molteplici, forse non tutte valide ma degne di esplorazione. Sta di fatto che l'utenza Linux su desktop si allarga, i numeri sono ancora piccini ma in costante crescita, e la quantita' di apporti non cresce con lo stesso ritmo.
Se un pugno di tecnici altamente specializzati hanno prodotto i risultati oggi sotto gli occhi di tutti, creare e mantenere un ecosistema realmente attivo e partecipativo puo' portarci la' dove nessun PC e' mai giunto prima.
martedì 25 agosto 2009
Sentimento a 8 Bit
Tra i diversi articoli interessanti apparsi (stranamente, essendo estate) negli ultimi giorni, uno mi ha colpito per due distinti e diametralmente opposti motivi: il fascino del tema toccato, e la sua profonda ingenuita'.
Il brano e' questo qua (originariamente letto sulle pagine del New York Times), e parla delle tecnologie disponibili e/o in fase di sviluppo per l'analisi semantica dei contenuti sparpagliati sul web e l'estrazione di dati statistici. Il fine utilitaristico di tale procedura sarebbe, in sintesi, valutare se un dato prodotto (o avvenimento, o azienda...) e' recepita benignamente o malignamente dal pubblico, consultando blogs, news, tweets ed altre disparate fonti per trarne l'opinione di fondo e convertirla in un valore numerico facilmente rappresentabile in un grafico.
La bellezza gustosamente intellettuale ed accademica di codesti strumenti di misura dell'umore, calibri per i sentimenti e righelli dell'animo, e' pero' a parer mio esclusivamente intellettuale ed accademica: allo stato dei fatti attuale, hanno una utilita' prossima a zero.
Facciamo un semplice esempio pratico, partendo da un prodotto a caso. Per comodita' e pigrizia prendo un libro recentemente recensito sul blog di una amica, "Quella Stronza del mio Capo" (sicuramente non e' il mio genere...). Ne piglio il titolo e lo cerco su Google Blogs, motore di ricerca della blogosfera; risultato: 21 menzioni, riportate ovviamente in linguaggio naturale, dunque da analizzare rigo per rigo innanzitutto per capire se effettivamente si sta parlando di quell'opera e poi per trarne l'impressione positiva o negativa avuta dall'autore del post. Ricopio il titolo e lo cerco su Anobii, community dedicata a persone che vogliono condividere le proprie letture con altri appassionati (e di cui sono membro); risultato: 50 voti, espressi per mezzo di un semplice form di rating e rappresentati in forma di media (le stelline a fianco della copertina) e tabellare (le lineette che appaiono al paragrafo "Dettagli del libro").
Ora: senza nulla togliere al valore certamente piu' completo e puntuale che puo' avere un post su un blog, val la pena dispiegare fior di risorse computazionali per setacciare l'Internet, individuare e cavare un dato che invece gia' mi viene fornito altrove secondo la modalita' a me piu' confacente (un numeretto) e con un campione di utenza ampio piu' del doppio?
Da una parte, quella dei brillanti ricercatori descritti nell'articolo di apertura, si cerca di far comprendere al computer la complessa ed intricata mente umana - e di conseguenza prima di tutto il linguaggio con cui essa si manifesta - per trarne delle conclusioni stocastiche; dall'altra, quella dell'utenza, si cerca piu' o meno consapevolmente di assecondare il computer, e strumenti semplici di interazione garantiscono una piu' immediata partecipazione e condivisione, nonche' una piu' radicata sicurezza - cliccare su una stellina da 1 a 4 difficilmente puo' portare ad errori grammaticali di cui vergognarsi col prossimo.
Ad oggi, disponendo sulle nostre scrivanie di PC fondamentalmente stupidi in grado solo di immagazzinare e visualizzare valori finiti, le applicazioni (web e non) tendono a delegare all'utente la classificazione del contenuto, vincolandolo a ragionare sullo stesso piano della macchina, appunto secondo valori finiti: da qui l'introduzione di tags da assegnare a documenti e foto, flags da settare per memorizzare l'importanza relativa di un dato, stelline per misurarne l'apprezzamento...
Interessante notare pero' come codesti paletti e restrizioni non siano solo soluzioni temporanee indotte dalla necessita' (in quanto come detto il computer non sarebbe in grado di estrarre tali metadati emozionali da solo e dunque l'utente dovrebbe proprio farne a meno), ma al contrario secondi i canoni moderni sono visti come rivoluzionari, condizionano la psicologia della interazione uomo/macchina e sono considerati naturali per chiunque. Da questa tendenza emerge del resto il discreto successo delle community wiki (in cui ciascuno aggiunge qualcosina in merito al suo argomento preferito), l'enorme successo del microblogging (ove non e' necessario stilare sermoni come i miei per esporre il proprio pensiero, 140 caratteri bastano ed avanzano), il gigantesco successo dei social network (in cui i contenuti una volta immessi rimbalzano da un utente all'altro, essendo condivisi con un semplice click, ed ogni tanto spunta un breve commento), tutte modalita' in cui l'utilizzatore fa poco dicendo tanto - o quantomeno piu' che non facendo nulla...
Qual'e' la conclusione di questa serie di osservazioni? Assolutamente nessuna. La riduzione della complessita' dell'espressione non e' ne' giusta ne' sbagliata, in quanto da una parte diminuisce la varieta' ma dall'altra garantisce un coinvolgimento di piu' persone, e va presa per quella che e': una evoluzione antropologica. Proseguira' fino all'estremo di ridurre l'intera comunicazione umana ad un ininterrotto flusso di emoticons? Si invertira' al raggiungimento di un maggiore grado di coinvolgimento delle future generazioni di utenti, smaniosi di dir la propria in modo approfondito? Se sapessi predire il futuro starei qui a scrivere su un blog anziche' correre a giocare al SuperEnalotto?
Nel frattempo dobbiamo accontentarci di quel che abbiamo, ovvero un computer che conserva numeri. E dentro questi numeri, volenti o nolenti, dobbiamo farci stare tutto: cifre, informazioni, misure. E sentimenti.
Il brano e' questo qua (originariamente letto sulle pagine del New York Times), e parla delle tecnologie disponibili e/o in fase di sviluppo per l'analisi semantica dei contenuti sparpagliati sul web e l'estrazione di dati statistici. Il fine utilitaristico di tale procedura sarebbe, in sintesi, valutare se un dato prodotto (o avvenimento, o azienda...) e' recepita benignamente o malignamente dal pubblico, consultando blogs, news, tweets ed altre disparate fonti per trarne l'opinione di fondo e convertirla in un valore numerico facilmente rappresentabile in un grafico.
La bellezza gustosamente intellettuale ed accademica di codesti strumenti di misura dell'umore, calibri per i sentimenti e righelli dell'animo, e' pero' a parer mio esclusivamente intellettuale ed accademica: allo stato dei fatti attuale, hanno una utilita' prossima a zero.
Facciamo un semplice esempio pratico, partendo da un prodotto a caso. Per comodita' e pigrizia prendo un libro recentemente recensito sul blog di una amica, "Quella Stronza del mio Capo" (sicuramente non e' il mio genere...). Ne piglio il titolo e lo cerco su Google Blogs, motore di ricerca della blogosfera; risultato: 21 menzioni, riportate ovviamente in linguaggio naturale, dunque da analizzare rigo per rigo innanzitutto per capire se effettivamente si sta parlando di quell'opera e poi per trarne l'impressione positiva o negativa avuta dall'autore del post. Ricopio il titolo e lo cerco su Anobii, community dedicata a persone che vogliono condividere le proprie letture con altri appassionati (e di cui sono membro); risultato: 50 voti, espressi per mezzo di un semplice form di rating e rappresentati in forma di media (le stelline a fianco della copertina) e tabellare (le lineette che appaiono al paragrafo "Dettagli del libro").
Ora: senza nulla togliere al valore certamente piu' completo e puntuale che puo' avere un post su un blog, val la pena dispiegare fior di risorse computazionali per setacciare l'Internet, individuare e cavare un dato che invece gia' mi viene fornito altrove secondo la modalita' a me piu' confacente (un numeretto) e con un campione di utenza ampio piu' del doppio?
Da una parte, quella dei brillanti ricercatori descritti nell'articolo di apertura, si cerca di far comprendere al computer la complessa ed intricata mente umana - e di conseguenza prima di tutto il linguaggio con cui essa si manifesta - per trarne delle conclusioni stocastiche; dall'altra, quella dell'utenza, si cerca piu' o meno consapevolmente di assecondare il computer, e strumenti semplici di interazione garantiscono una piu' immediata partecipazione e condivisione, nonche' una piu' radicata sicurezza - cliccare su una stellina da 1 a 4 difficilmente puo' portare ad errori grammaticali di cui vergognarsi col prossimo.
Ad oggi, disponendo sulle nostre scrivanie di PC fondamentalmente stupidi in grado solo di immagazzinare e visualizzare valori finiti, le applicazioni (web e non) tendono a delegare all'utente la classificazione del contenuto, vincolandolo a ragionare sullo stesso piano della macchina, appunto secondo valori finiti: da qui l'introduzione di tags da assegnare a documenti e foto, flags da settare per memorizzare l'importanza relativa di un dato, stelline per misurarne l'apprezzamento...
Interessante notare pero' come codesti paletti e restrizioni non siano solo soluzioni temporanee indotte dalla necessita' (in quanto come detto il computer non sarebbe in grado di estrarre tali metadati emozionali da solo e dunque l'utente dovrebbe proprio farne a meno), ma al contrario secondi i canoni moderni sono visti come rivoluzionari, condizionano la psicologia della interazione uomo/macchina e sono considerati naturali per chiunque. Da questa tendenza emerge del resto il discreto successo delle community wiki (in cui ciascuno aggiunge qualcosina in merito al suo argomento preferito), l'enorme successo del microblogging (ove non e' necessario stilare sermoni come i miei per esporre il proprio pensiero, 140 caratteri bastano ed avanzano), il gigantesco successo dei social network (in cui i contenuti una volta immessi rimbalzano da un utente all'altro, essendo condivisi con un semplice click, ed ogni tanto spunta un breve commento), tutte modalita' in cui l'utilizzatore fa poco dicendo tanto - o quantomeno piu' che non facendo nulla...
Qual'e' la conclusione di questa serie di osservazioni? Assolutamente nessuna. La riduzione della complessita' dell'espressione non e' ne' giusta ne' sbagliata, in quanto da una parte diminuisce la varieta' ma dall'altra garantisce un coinvolgimento di piu' persone, e va presa per quella che e': una evoluzione antropologica. Proseguira' fino all'estremo di ridurre l'intera comunicazione umana ad un ininterrotto flusso di emoticons? Si invertira' al raggiungimento di un maggiore grado di coinvolgimento delle future generazioni di utenti, smaniosi di dir la propria in modo approfondito? Se sapessi predire il futuro starei qui a scrivere su un blog anziche' correre a giocare al SuperEnalotto?
Nel frattempo dobbiamo accontentarci di quel che abbiamo, ovvero un computer che conserva numeri. E dentro questi numeri, volenti o nolenti, dobbiamo farci stare tutto: cifre, informazioni, misure. E sentimenti.
domenica 23 agosto 2009
Smashing Wallpapers
Pubblicato da
Roberto -MadBob- Guido
alle
01:06
2
commenti
Etichette:
code,
development,
inutility,
tools,
web
L'estate sta finendo, ed un anno se ne va. Ma di "diventare grande" non se ne parla proprio, anzi credo che questa sia stata l'estate in cui abbia maggiormente impiegato del tempo appresso a programmini di dubbia utilita' (TuxChan), opere lasciate un po' in sospeso (Lobotomy). e frammenti sparsi qua e la' (prossimamente faro' cenno alla mia avventura con Mojito).
Ma in fin dei conti non me ne rammarico: di Lobotomy posso dire di aver iniziato a far qualcosa, dopo mesi o addirittura anni di inerzia, i contributi occasionali ai progetti altrui sono sempre cosa ben fatta (tantopiu' se sono componenti di una piattaforma operativa come Moblin, una delle poche speranze open contro Symbian in ambiente mobile), e i programmini scemi sono sempre utili a sperimentare cose nuove e ad arricchire la base di applicazioni direttamente rivolte all'utenza finale con poco sforzo.
Tant'e' che ieri ne ho realizzata un'altra.
Smashing Wallpapers (che devo ancora trovar la voglia di predisporre al rilascio... Nei prossimi giorni apparira' su BarberaWare) e' una utility che permette di scaricare i graziosi wallpapers che il sito di Smashing Magazine mette a disposizione ogni mese (qui quelli di agosto 2009), e caratterizzati dalla feature di riportare - in armonia con il resto della grafica - il calendario completo del mese in corso; informazione non banale, considerando che non so piu' quante volte alla settimana devo aprire il calendarietto integrato nell'orologio del desktop environment per sapere in che giorno della settimana cade una certa data e decidere se e quando piazzare un incontro o un appuntamento.
Modalita' di utilizzo del programma: metterlo nella lista di esecuzione automatica del proprio ambiente grafico e dimenticarsene. Ad ogni avvio del sistema controlla se il wallpaper del mese corrente e' gia presente, se c'e' si chiude e se non c'e' va a cercare i nuovi contenuti, li scarica e si palesa nella barra di notifica. Da li', con una essenziale interfaccia Clutter si sceglie quello preferito, lo si seleziona, ed esso viene scaricato ed applicato. Fine.
Piazzo qui l'oramai abituale video, anche se per qualche motivo Vimeo me lo mostra solo a smozzichi ed in determinate circostanze (non identificate), spero altri abbiano maggiore fortuna:
Basta cazzeggio programmatorio, da lunedi si torna a lavorare.
Ma in fin dei conti non me ne rammarico: di Lobotomy posso dire di aver iniziato a far qualcosa, dopo mesi o addirittura anni di inerzia, i contributi occasionali ai progetti altrui sono sempre cosa ben fatta (tantopiu' se sono componenti di una piattaforma operativa come Moblin, una delle poche speranze open contro Symbian in ambiente mobile), e i programmini scemi sono sempre utili a sperimentare cose nuove e ad arricchire la base di applicazioni direttamente rivolte all'utenza finale con poco sforzo.
Tant'e' che ieri ne ho realizzata un'altra.
Smashing Wallpapers (che devo ancora trovar la voglia di predisporre al rilascio... Nei prossimi giorni apparira' su BarberaWare) e' una utility che permette di scaricare i graziosi wallpapers che il sito di Smashing Magazine mette a disposizione ogni mese (qui quelli di agosto 2009), e caratterizzati dalla feature di riportare - in armonia con il resto della grafica - il calendario completo del mese in corso; informazione non banale, considerando che non so piu' quante volte alla settimana devo aprire il calendarietto integrato nell'orologio del desktop environment per sapere in che giorno della settimana cade una certa data e decidere se e quando piazzare un incontro o un appuntamento.
Modalita' di utilizzo del programma: metterlo nella lista di esecuzione automatica del proprio ambiente grafico e dimenticarsene. Ad ogni avvio del sistema controlla se il wallpaper del mese corrente e' gia presente, se c'e' si chiude e se non c'e' va a cercare i nuovi contenuti, li scarica e si palesa nella barra di notifica. Da li', con una essenziale interfaccia Clutter si sceglie quello preferito, lo si seleziona, ed esso viene scaricato ed applicato. Fine.
Piazzo qui l'oramai abituale video, anche se per qualche motivo Vimeo me lo mostra solo a smozzichi ed in determinate circostanze (non identificate), spero altri abbiano maggiore fortuna:
Basta cazzeggio programmatorio, da lunedi si torna a lavorare.
giovedì 20 agosto 2009
ToDo, UnDo
Uno dei miei pregi come programmatore e' che sono costantemente ispirato e quotidianamente espello idee. Uno dei miei difetti come programmatore e' che non riesco a concentrarmi su un progetto per il tempo necessario alla sua realizzazione, che subito passo ad un'altro.
Da tempo ho preso l'abitudine di appuntarmi le varie piu' o meno dettagliate folgorazioni che mi colgono, sempre col proposito di tenerle sott'occhio ed integrarle via via che scopro nuove tecnologie e metodi, ma inevitabilmente la coda diventa sempre piu' difficile da smaltire a causa dei tempi di realizzazione che avrebbe ogni oggetto, e sebbene nell'ultimo periodo abbia avuto modo di concretizzare qualcosa qua e la' la massa di progetti latenti diventa sempre piu' imponente. "Il genio e' per l'1% ispirazione e per il 99% traspirazione" (Thomas Edison), e non essendo io un genio sono completamente sbilanciato su un 90% del primo ingrediente ed un 10% del secondo.
Pertanto periodicamente espongo le mie (piu' o meno corrette) illuminazioni pubblicamente, nella speranza che qualcuno sull'Internet possa inciamparvi e magari essere altrettanto ispirato: non credo che avro' mai modo e maniera di far tutto, dunque tanto vale che lo faccia qualcun'altro. Ogni tanto pubblico un post su questo blog, qualche volta riporto sull'Alambicco di BarberaWare, e quando raggiungo una massa critica stipulo una lista forfettaria. Questa e' una di queste occasioni.
Alla faccia dei brevetti...
Da tempo ho preso l'abitudine di appuntarmi le varie piu' o meno dettagliate folgorazioni che mi colgono, sempre col proposito di tenerle sott'occhio ed integrarle via via che scopro nuove tecnologie e metodi, ma inevitabilmente la coda diventa sempre piu' difficile da smaltire a causa dei tempi di realizzazione che avrebbe ogni oggetto, e sebbene nell'ultimo periodo abbia avuto modo di concretizzare qualcosa qua e la' la massa di progetti latenti diventa sempre piu' imponente. "Il genio e' per l'1% ispirazione e per il 99% traspirazione" (Thomas Edison), e non essendo io un genio sono completamente sbilanciato su un 90% del primo ingrediente ed un 10% del secondo.
Pertanto periodicamente espongo le mie (piu' o meno corrette) illuminazioni pubblicamente, nella speranza che qualcuno sull'Internet possa inciamparvi e magari essere altrettanto ispirato: non credo che avro' mai modo e maniera di far tutto, dunque tanto vale che lo faccia qualcun'altro. Ogni tanto pubblico un post su questo blog, qualche volta riporto sull'Alambicco di BarberaWare, e quando raggiungo una massa critica stipulo una lista forfettaria. Questa e' una di queste occasioni.
- Binding Glib per FUSE. L'idea emerse qualche tempo addietro, quando per lavoro iniziai lo sviluppo di un filesystem in userspace che doveva maneggiare GObjects pescati da una libreria ad hoc e ricevere eventi da una connessione DBus (anch'essa mantenuta per mezzo del binding Glib). Data la natura interna di FUSE ho dovuto aprire un thread separato in cui far girare il mainloop, che appunto restasse in ascolto sulla connessione DBus, ma l'ideale sarebbe implementare il mainloop di FUSE dentro quello Glib e far lavorare insieme i due layer. L'optimum sarebbe avere un GObject che astragga le funzioni low-level di FUSE e le richiami nel loop Glib, in modo che estendendo quello sia banale realizzare un nuovo filesystem pur godendo di tutto lo stack Glib e della pletora di sottolibrerie disponibili.
- Rsync wizard. Qualche settimana addietro, intimorito dagli inquietanti rumorini provenienti dall'interno del mio tablet, decisi che era tempo di adottare una soluzione strutturata per il backup. Diedi una occhiata in giro e trovai solo soluzioni immensamente complesse, con server da configurare e centinaia di parametri da settare, nonche' daemons in esecuzione piu' o meno permanente, ed alla fine optai per il metodo in assoluto piu' scontato: una chiave SSH, rsync ed uno script in cron. Per quanto non perfetto questo meccanismo credo soddisfi la necessita' della stragrande maggioranza dell'utenza domestica, ed ha l'unico difetto di richiedere una serie di passaggi da linea di comando non propriamente adeguati per un occasionale utente. L'idea sarebbe dunque quella di predisporre un frontend che provveda a costruire la riga con cui invocare rsync, metterla in cron ed eventualmente creare ed installare le chiavi SSH (onde poter procedere al trasferimento dei dati da un PC all'altro senza dover immettere la password; di norma il server e' installabile con una configurazione funzionale di default con qualsiasi distribuzione). Progetto estremamente semplice da imbastire, ma non completamente banale se si vuole una soluzione finale a prova di utonto, piu' una sfida di design che di programmazione.
- Distribuzione dei files Torrent via GIT. Questo non e' un vero e proprio progetto, quanto piu' uno spunto di indagine: emerse ai tempi della notizia dell'acquisizione di ThePirateBay e della prossima imminente chiusura del tracker torrent piu' noto al pianeta, e sebbene molti altri tracker siano disponibili in Rete e risulti ovvio che il ritmo di chiusura sia piu' basso di quello di creazione di nuovi snodi (rendendo infinetesimale il rischio di trovarsi senza un punto di riferimento) varrebbe secondo me la pena individuare una strategia completamente decentralizzata, quale appunto quella adottata dagli SCM distribuiti - GIT, ma anche Mercurial o Bazaar.
- Vista partizionata in Nautilus. Ho sempre trovato Baobab un programma assai utile: permette infatti di visualizzare il filesystem con spicchi che graficamente rappresentano lo spazio occupato dai vari files (e dalle cartelle che tali files contengono), permettendo di individuare in un colpo d'occhio le aree in cui per un motivo o per l'altro si sono accumulati dati in eccesso e di cui dunque ci si puo' sbarazzare per recuperare preziosa ROM. Tale funzionalita' sarebbe molto utile se integrata a mo' di "vista" direttamente in Nautilus, il filemanager di Gnome: si tratterebbe di prelevare il widget originario di Baobab ed includerlo dentro l'applicativo sfruttando la gia' esistente interfaccia programmatoria per tale frangente, ben poco documentata ma usata da questo hack (da usare come esempio). Rapido, ma merita qualche attenzione nel perfezionamento nell'algoritmo che computa la dimensione delle cartelle, al momento un po' lentuccio.
- Binding Bash per DBus. Il nome e' molto evocativo, anche se ai fatti si tratterebbe di qualcosa di estremamente semplice: un set di micro-applicativi (o uno solo, con piu' opzioni) da invocare da linea di comando e che permettano di dialogare in modo flessibile con DBus (ed ovviamente con i servizi esposti sul canale). Scopo del gioco: avere modo di scrivere script Bash che sfruttino i piu' avanzati servizi di sistema, dall'interrogazione di NetworkManager (per sapere se c'e' connessione o meno) alla manipolazione dello screensaver. Il compito e' meno banale di quanto non ci si possa aspettare, in quanto i metodi invocabili per mezzo di DBus possono presentarsi in una infinita combinazione di parametri, tipi di parametri e valori di ritorno, che dovrebbero essere trattati nel modo piu' trasparente possibile magari sfruttando le tecniche di introspezione proprie del protocollo onde fornire una interfaccia di utilizzo semplice.
- Integrazione autenticazione USB. Nell'ultimo periodo ho constatato (ma forse solo perche' non me ne sono accorto prima...) un incremento dei metodi di autenticazione disponibili su Linux, che fanno uso di PAM nei modi piu' disparati. Tra questi ho trovato particolarmente simpatico questo meccanismo, che coinvolge una pennetta USB da usare come chiave fisica di accesso al PC: accessibile immediatamente a tutti (contrariamente agli scanner per impronte digitali, o alle smartcard), sufficientemente sicuro e di garantito effetto con gli amici. Non sarebbe niente male integrare questo sistema nel pannello "Utenti" di Gnome, si' da mettere a portata di mouse la procedura di creazione e verifica delle chiavette e la poca configurazione richiesta.
- FUSE Installer. Tutti gli utenti informatici casalinghi vengono sconvolti da una particolare feature di Mac: i programmi si installano copiandoli in una apposita cartella, e si disinstallano rimuovendo la cartella stessa. Niente wizards "avanti avanti avanti" a la Windows, niente accrocchi strani a la Linux. Da utente tecnico rimango piu' che soddisfatto del package management tipico dei sistemi Linux (qualsiasi distribuzione ha oramai un sistema automatico di risoluzione delle dipendenze, che evita di portarsi appresso mega e mega di librerie con ogni pacchetto), ma ammetto che molti limiti ancora esistano e che il meccanismo vada al di la' della mentalita' irrimediabilmente compromessa dell'utenza (inutile spiegare che per cercare ed installare qualcosa si deve aprire Synaptic, una forza oscura li spingera' sempre a cercare il setup.exe su Internet). Dunque perche' non provare ad unire il meglio dei due mondi, Mac e Linux? Un filesystem FUSE farebbe le veci della "apposita cartella" in cui copiare gli archivi prelevati in Rete, ed internamente dovrebbe provvedere ad analizzare i nuovi files ivi introdotti e trattarli nella maniera che piu' gli si confa': se possono essere gestito direttamente dal package manager della distribuzione si installano nel modo previsto, se sono pacchettizzati in qualche altro formato li si converte con alien, se sono archivi di sorgenti li si decomprime e si esegue il solito "./configure ; make ; sudo make install", il tutto tentando di fare del proprio meglio con la risoluzione e l'installazione delle dipendenze. PackageKit dovrebbe fornire un supporto decente per triangolare i nomi delle dipendenze, il resto... E' lasciato alla fantasia dell'implementatore.
- Versioning degli snippets. Una idea non mia, bensi' presa da qui e che, al di la' della fattibilita', ritengo ingegnosa: assegnare un identificativo ai frammenti di codice comunemente sparpagliati in Rete, in modo da saperli tracciare ed aggiornare qualora avvenga qualche miglioria o correzione. La realizzazione dell'impresa sarebbe quantomeno difficoltosa: occorrerebbe innanzitutto assegnare gli identificativi, e dunque o convincere le varie piattaforme di condivisione degli snippets a farlo o importare tutto il loro materiale su un'altro sito ad hoc che provveda alla trasformazione, e poi integrare metodi di sincronizzazione all'interno dei maggiori IDE, si' che siano in grado di provvedere da soli alla verifica di aggiornamenti, oppure realizzare un deamon dedicato che dato l'indice dei files sorgenti da sorvegliare implementi il ciclo di controllo in modo centralizzato. Forse utopico, ma lo lascio come spunto.
Alla faccia dei brevetti...
venerdì 14 agosto 2009
Lobotomy Summer of Code
Pubblicato da
Roberto -MadBob- Guido
alle
01:26
0
commenti
Etichette:
development,
lobotomy,
synapse
Per chi non lo avesse notato (ovvero immagino tutti i lettori di questo blog, divisi tra Facebook e l'RSS), nella casella dell'account Flickr su questa pagina hanno iniziato a spuntare alcuni screenshots, piu' precisamente uno al giorno negli ultimi quattro giorni. Essi sono per documentare lo stato dei lavori nella prima implementazione di Synapse, componente dell'assai piu' vasto progetto Lobotomy.
Dopo lungo, lunghissimo periodo di meditazione, nonche' di impegno su altri progetti e lavori, ho infine profittato di queste ferie estive per iniziare a mettere insieme un mezzo prototipo della baracca, per valutare la concretezza del modello di interazione previsto e misurarne l'efficacia. Proprio per questo motivo, nonche' per tenere la mano allenata con Java e PHP, e in rispetto a quanto gia' accennato in un lontano passato, e per facilitare eventuali sessioni di test pubblico (tenetevi pronti a farmi da beta-tester!), la prima implementazione e' realizzata con l'apporto del solito WebToolkit di Google, e Synapse non e' altro che una applicazione Javascript con un backend che rappresenta l'effettivo motore relazionale (anche se al momento tutti i dati sono malamente cablati a mano).
La prima cosa che salta all'occhio guardando gli screenshots e' che l'applicazione e' confinata entro un rettangolo anziche' estendersi su tutta la pagina renderizzata nel browser: ebbene, quel rettangolo e' di 480x640 pixel, ovvero la dimensione dello schermo del FreeRunner (volgarmente noto come "OpenMoko"). Questa e' infatti la prima piattaforma su cui intendo usare Lobotomy: una scelta certamente azzardata, in quanto porta una serie di problematiche tecniche (l'OpenMoko va smanettato non poco per apportare una modifica quale la sostituzione dell'intero ambiente grafico) e di interazione (lo schermo nelle dimensioni reali e' proprio piccolo, molte cose vanno divise obbligatoriamente su piu' pannelli), ma tanto vale porsi da subito nelle condizioni peggiori affinche' poi lo sviluppo su piattaforma PC (e non solo...) sia tutto in discesa.
Allo stato attuale una parte del parsing e della costruzione dinamica dei Thoughts e' completa, sebbene manchino alcuni tipi di dati elementari per i metadati (ad esempio non c'e' ancora modo di esprimere un array di valori), alcuni widgets basilari ci sono e come detto il backend e' un'unico ammasso di XML scritto a mano su cui puo' essere eseguito una query sola, quella per l'estrazione del file README che di default appare all'avvio. Comunque fino a questo punto non sono emersi particolari ostacoli alla realizzazione dell'idea, e gli unici problemi li ho riscontrati quando mi son messo a giocare con gli effetti da applicare ai vari elementi dell'interfaccia (il framework per le Animations in GWT e' sufficientemente ostico), ovvero su cose non concernenti il modello Lobotomy in se'.
Ulteriori aggiornamenti a seguire, certamente prima della fine delle ferie!
Dopo lungo, lunghissimo periodo di meditazione, nonche' di impegno su altri progetti e lavori, ho infine profittato di queste ferie estive per iniziare a mettere insieme un mezzo prototipo della baracca, per valutare la concretezza del modello di interazione previsto e misurarne l'efficacia. Proprio per questo motivo, nonche' per tenere la mano allenata con Java e PHP, e in rispetto a quanto gia' accennato in un lontano passato, e per facilitare eventuali sessioni di test pubblico (tenetevi pronti a farmi da beta-tester!), la prima implementazione e' realizzata con l'apporto del solito WebToolkit di Google, e Synapse non e' altro che una applicazione Javascript con un backend che rappresenta l'effettivo motore relazionale (anche se al momento tutti i dati sono malamente cablati a mano).
La prima cosa che salta all'occhio guardando gli screenshots e' che l'applicazione e' confinata entro un rettangolo anziche' estendersi su tutta la pagina renderizzata nel browser: ebbene, quel rettangolo e' di 480x640 pixel, ovvero la dimensione dello schermo del FreeRunner (volgarmente noto come "OpenMoko"). Questa e' infatti la prima piattaforma su cui intendo usare Lobotomy: una scelta certamente azzardata, in quanto porta una serie di problematiche tecniche (l'OpenMoko va smanettato non poco per apportare una modifica quale la sostituzione dell'intero ambiente grafico) e di interazione (lo schermo nelle dimensioni reali e' proprio piccolo, molte cose vanno divise obbligatoriamente su piu' pannelli), ma tanto vale porsi da subito nelle condizioni peggiori affinche' poi lo sviluppo su piattaforma PC (e non solo...) sia tutto in discesa.
Allo stato attuale una parte del parsing e della costruzione dinamica dei Thoughts e' completa, sebbene manchino alcuni tipi di dati elementari per i metadati (ad esempio non c'e' ancora modo di esprimere un array di valori), alcuni widgets basilari ci sono e come detto il backend e' un'unico ammasso di XML scritto a mano su cui puo' essere eseguito una query sola, quella per l'estrazione del file README che di default appare all'avvio. Comunque fino a questo punto non sono emersi particolari ostacoli alla realizzazione dell'idea, e gli unici problemi li ho riscontrati quando mi son messo a giocare con gli effetti da applicare ai vari elementi dell'interfaccia (il framework per le Animations in GWT e' sufficientemente ostico), ovvero su cose non concernenti il modello Lobotomy in se'.
Ulteriori aggiornamenti a seguire, certamente prima della fine delle ferie!
martedì 11 agosto 2009
L'Arte della Pubblicita'
Negli ultimi giorni, navigando il web e piu' in particolare alcuni siti italiani, mi e' cascato l'occhio su certi banner cosi' interessanti che ho deciso di riportarne un commento qui sebbene il tema sia abbastanza fuori dal topic del blog.
Il prodotto pubblicizzato e' un registry cleaner per Windows, uno di quei classici programmini che devono essere usati per tentare di mettere una pezza in quell'enorme falla architetturale tipica dei sistemi operativi Microsoft che appunto e' il registro di sistema, ma la cura riposta nel confezionare tale capolavoro di marketing fa commuovere.
Cliccando sul banner si e' riportati su codesta pagina, in cui non si puo' fare a meno di constatare il grande risalto che viene dato ai concetti "velocizza il PC" e "elimina gli errori". Ebbene: chi ha un minimo di consapevolezza tecnica ed ha avuto a che fare con l'utenza informatica casalinga media, sa che questi sono i due termini in assoluto piu' usati da chi senza arte ne' parte detiene un computer in casa: "velocizzare" e "gli errori". Riferendosi a tali nozioni si e' sicuri di attirare l'attenzione e toccare la sensibilita' di una ampia fascia di rappresentanti della fascia consumer, soprattutto quelli rimasti delusi dall'amico smanettone di turno che non e' riuscito a risolvere il suo problema, che di norma e' riassumibile con "Ho il computer che va in errore, cosa devo fare?". Poco importa che l'indicazione "gli errori" si riferisca ad entita' totalmente aleatorie - se e' al plurale si suppone ce ne siano tanti, i quali si esprimono in maniera diversa e richiedono soluzioni diverse. Se non si esplicita di quale errore si parla, come si fa a risalire alla relativa sistemazione? -, o che il verbo "velocizzare" sia usato totalmente senza cognizione di causa essendo i PC moderni macchine da miliardi di operazioni al secondo e tanto dovrebbe bastare; il punto sta nell'adottare un lessico famigliare, non necessariamente corretto ne' tantomeno con un significato effettivo ma comprensibile, e far sapere all'utente che c'e' qualcuno di esperto che riesce perfettamente a comprendere il suo sentimento di frustrazione dinnanzi al complesso marchingegno elettronico e vuole aiutarlo.
Ma la perfezione psico/grafica della pagina linkata dai banner in oggetti non si limita all'intestazione colorata: scorrendo verso il basso la lunga e dettagliata descrizione il tenore dei contenuti varia con costanza geometrica, passando da "Scansione ultra-veloce e riparazione automatica" (definizione user-proof) a "Errori di Componenti ActiveX" (definizione da smanettoni), ottenendo il duplice risultato di accontentare l'ego del visitatore piu' smaliziato ed accorto (che poi lo voglio vedere un sedicente espero Windows che clicca su un banner "Velocizza il tuo PC"...) ed insieme fornire quella giusta quantita' di terminologia specifica indispensabile per dare una credibilita' all'insieme - se non usa un lessico tecnico, che tecnico e'?
Un'ultima chicca, solo per intenditori. Nel paragrafo "Testimonianze", l'ultimo della pagina, vengono riportati due commenti rilasciati da utilizzatori evidentemente molto soddisfatti del prodotto: un utente casalingo ed uno enterprise (certamente chiamato in causa per strizzare l'occhio a coloro che dovrebbero acquistare la versione "Pro" dell'applicazione). Guardateli bene, leggete i nomi e soprattutto la provenienza: ma poteva non essere che l'utente sfigato fosse un napoletano e l'imprenditore un brianzolo? Quali migliori testimonial potevano essere rintracciati (o inventati...) per promuovere il programma?
Ho sperato in un qualche tentativo di auto-rilevamento del sistema operativo in uso che cercasse di aiutarmi a scaricare la versione XP o Vista del programma, ma con scarso risultato; non mi resta che sperare che sul log sia rimasta traccia del tentativo di download da parte di una macchina Linux, e che cio' provochi un attimo di ilarita' per il povero admin dall'altra parte della barricata.
Un merito a Microsoft bisogna riconoscerlo: senza di lei e senza la sua lunga opera di lobotomizzazione delle masse digitali, noi informatici consapevoli non potremmo godere di tali perle.
Il prodotto pubblicizzato e' un registry cleaner per Windows, uno di quei classici programmini che devono essere usati per tentare di mettere una pezza in quell'enorme falla architetturale tipica dei sistemi operativi Microsoft che appunto e' il registro di sistema, ma la cura riposta nel confezionare tale capolavoro di marketing fa commuovere.
Cliccando sul banner si e' riportati su codesta pagina, in cui non si puo' fare a meno di constatare il grande risalto che viene dato ai concetti "velocizza il PC" e "elimina gli errori". Ebbene: chi ha un minimo di consapevolezza tecnica ed ha avuto a che fare con l'utenza informatica casalinga media, sa che questi sono i due termini in assoluto piu' usati da chi senza arte ne' parte detiene un computer in casa: "velocizzare" e "gli errori". Riferendosi a tali nozioni si e' sicuri di attirare l'attenzione e toccare la sensibilita' di una ampia fascia di rappresentanti della fascia consumer, soprattutto quelli rimasti delusi dall'amico smanettone di turno che non e' riuscito a risolvere il suo problema, che di norma e' riassumibile con "Ho il computer che va in errore, cosa devo fare?". Poco importa che l'indicazione "gli errori" si riferisca ad entita' totalmente aleatorie - se e' al plurale si suppone ce ne siano tanti, i quali si esprimono in maniera diversa e richiedono soluzioni diverse. Se non si esplicita di quale errore si parla, come si fa a risalire alla relativa sistemazione? -, o che il verbo "velocizzare" sia usato totalmente senza cognizione di causa essendo i PC moderni macchine da miliardi di operazioni al secondo e tanto dovrebbe bastare; il punto sta nell'adottare un lessico famigliare, non necessariamente corretto ne' tantomeno con un significato effettivo ma comprensibile, e far sapere all'utente che c'e' qualcuno di esperto che riesce perfettamente a comprendere il suo sentimento di frustrazione dinnanzi al complesso marchingegno elettronico e vuole aiutarlo.
Ma la perfezione psico/grafica della pagina linkata dai banner in oggetti non si limita all'intestazione colorata: scorrendo verso il basso la lunga e dettagliata descrizione il tenore dei contenuti varia con costanza geometrica, passando da "Scansione ultra-veloce e riparazione automatica" (definizione user-proof) a "Errori di Componenti ActiveX" (definizione da smanettoni), ottenendo il duplice risultato di accontentare l'ego del visitatore piu' smaliziato ed accorto (che poi lo voglio vedere un sedicente espero Windows che clicca su un banner "Velocizza il tuo PC"...) ed insieme fornire quella giusta quantita' di terminologia specifica indispensabile per dare una credibilita' all'insieme - se non usa un lessico tecnico, che tecnico e'?
Un'ultima chicca, solo per intenditori. Nel paragrafo "Testimonianze", l'ultimo della pagina, vengono riportati due commenti rilasciati da utilizzatori evidentemente molto soddisfatti del prodotto: un utente casalingo ed uno enterprise (certamente chiamato in causa per strizzare l'occhio a coloro che dovrebbero acquistare la versione "Pro" dell'applicazione). Guardateli bene, leggete i nomi e soprattutto la provenienza: ma poteva non essere che l'utente sfigato fosse un napoletano e l'imprenditore un brianzolo? Quali migliori testimonial potevano essere rintracciati (o inventati...) per promuovere il programma?
Ho sperato in un qualche tentativo di auto-rilevamento del sistema operativo in uso che cercasse di aiutarmi a scaricare la versione XP o Vista del programma, ma con scarso risultato; non mi resta che sperare che sul log sia rimasta traccia del tentativo di download da parte di una macchina Linux, e che cio' provochi un attimo di ilarita' per il povero admin dall'altra parte della barricata.
Un merito a Microsoft bisogna riconoscerlo: senza di lei e senza la sua lunga opera di lobotomizzazione delle masse digitali, noi informatici consapevoli non potremmo godere di tali perle.
sabato 8 agosto 2009
TuxChan
Pubblicato da
Roberto -MadBob- Guido
alle
01:43
0
commenti
Etichette:
code,
development,
integration,
inutility,
web
Come sempre con l'approssimarsi delle vacanze estive, mentre amici e colleghi partono per trascorrere le ferie nei posti piu' disparati, io colgo l'occasione per sviluppare in santa pace un po' di software per conto mio. Sebbene dovrei lavorare su Lobotomy (ho finalmente iniziato la scrittura del parser di Synapse!), o dare qualche sistemata a GASdotto in vista della messa in opera prevista per settembre, o rifinire libopengdesktop ed aggiungere la pletora di funzionalita' ancora mancanti, in atmosfera vacanziera e di spensieratezza ho ben pensato di dedicare un pochino di tempo ad un ennesimo progettucolo: TuxChan.
La storia del perche' e percome sia arrivato a tale ispirazione la rimando ad un'altro post, per ora mi concentro sull'aspetto tecnico: esso e' un client desktop per 4chan, la popolare imageboard che dal 2003 convoglia il peggio del peggio del cazzeggio e da cui storicamente emergono alcuni dei piu' virali e devastanti meme.
In cosa consiste 4chan? In un sito estremamente brutto ed inutilizzabile in cui nei vari canali tematici si svolgono discussioni incentrate per lo piu' intorno alle immagini postate dagli utenti, ed in cui i contenuti vengono automaticamente cestinati via via che ne arrivano di nuovi. I materiali variano entro un range abbastanza vasto, non esistendo regole o comunque essendo moderatamente rispettate e non vigilate, il file rouge sembra essere il Giappone (Terra Promessa di molti geeks occidentali) ma nella stragrande maggioranza dei casi si tratta di fotografie divertenti (quantomeno secondo la cultura internettiana) oppure a sfondo sessuale.
A cosa serve 4chan? Assolutamente a nulla, se non a far perdere un po' di tempo ai giovanotti col pallino delle giapponeserie e senza nulla di piu' utile da fare che non stare a contemplare lo stream di immagini che freneticamente si susseguono sulle sue pagine.
E dunque, a cosa serve TuxChan? Agli utenti, ad avere una interfaccia un pochino piu' decorosa dell'originale e nella possibilita' di ricevere indirettamente i push sugli aggiornamenti senza stare a ricaricare manualmente la pagina web ogni due minuti (ed all'interno delle community che orbitano intorno a questo tipo di contenuti essere i primi a venire a conoscenza di qualcosa di nuovo e condividerlo con i pari gioca un ruolo sociale non secondario). A me, ad avere un pretesto per giocare finalmente un po' con Clutter.
Da tempo immemore cercavo un qualche applicativo che mi permettesse di mettere alla prova il toolkit, e non potevo scegliere momento migliore che non il recente rilascio della release stabile 1.0. E non mi sembra affatto male: nel giro di un paio di serate (in buona parte buttate appresso a GIO: non usate g_file_copy_async() !!!) e nello spazio di meno di 1000 righe di C (altro argomento su cui dovro' tornare prossimamente) ho ottenuto una interfaccia a parer mio soddisfacente, minimale e proprio per questo efficiente, con le immagini che scorrono ed un pannellino per configurare i channels da seguire. Per essere stabile e' stabile, e l'API pur essendo limitata permette di fare qualsiasi cosa, alla faccia di QtGraphicsView che ad ogni minor release cambia comportamento ed ha una interfaccia troppo complessa per essere fruibile rapidamente.
Come supponevo il paradigma che sta dietro a codesto strumento va un attimo compreso prima di essere utilizzato efficacemente: all'inizio si puo' restare spiazzati dinnanzi alla totale assenza di widgets complessi che implementino le varie modalita' di interazione con l'utente, ma una volta capacitatisi del fatto che qualsiasi cosa si disegni sullo schermo puo' essere spostato, ruotato, e fatto divenire un elemento che reagisce a degli eventi esterni, si comprende il segreto intrinseco del toolkit: permettere di fare di piu', con meno.
Potrei dilungarmi qui in merito ai rischi del non avere alcuna limitazione nella definizione della propria interfaccia, fatto che si presta ad essere preludio alla totale disgregazione della coerenza tra diverse applicazioni, ma per ora interrompo qui: ci sara' modo e maniera di tornare su questi argomenti quando il tutto sara' piu' radicalmente diffuso grazie all'apparente progressiva integrazione in GNOME, e ci si potra' basare su dati concreti anziche' su illazioni.
Maggiori news sulle mie avventure estive a seguire...
La storia del perche' e percome sia arrivato a tale ispirazione la rimando ad un'altro post, per ora mi concentro sull'aspetto tecnico: esso e' un client desktop per 4chan, la popolare imageboard che dal 2003 convoglia il peggio del peggio del cazzeggio e da cui storicamente emergono alcuni dei piu' virali e devastanti meme.
In cosa consiste 4chan? In un sito estremamente brutto ed inutilizzabile in cui nei vari canali tematici si svolgono discussioni incentrate per lo piu' intorno alle immagini postate dagli utenti, ed in cui i contenuti vengono automaticamente cestinati via via che ne arrivano di nuovi. I materiali variano entro un range abbastanza vasto, non esistendo regole o comunque essendo moderatamente rispettate e non vigilate, il file rouge sembra essere il Giappone (Terra Promessa di molti geeks occidentali) ma nella stragrande maggioranza dei casi si tratta di fotografie divertenti (quantomeno secondo la cultura internettiana) oppure a sfondo sessuale.
A cosa serve 4chan? Assolutamente a nulla, se non a far perdere un po' di tempo ai giovanotti col pallino delle giapponeserie e senza nulla di piu' utile da fare che non stare a contemplare lo stream di immagini che freneticamente si susseguono sulle sue pagine.
E dunque, a cosa serve TuxChan? Agli utenti, ad avere una interfaccia un pochino piu' decorosa dell'originale e nella possibilita' di ricevere indirettamente i push sugli aggiornamenti senza stare a ricaricare manualmente la pagina web ogni due minuti (ed all'interno delle community che orbitano intorno a questo tipo di contenuti essere i primi a venire a conoscenza di qualcosa di nuovo e condividerlo con i pari gioca un ruolo sociale non secondario). A me, ad avere un pretesto per giocare finalmente un po' con Clutter.
Da tempo immemore cercavo un qualche applicativo che mi permettesse di mettere alla prova il toolkit, e non potevo scegliere momento migliore che non il recente rilascio della release stabile 1.0. E non mi sembra affatto male: nel giro di un paio di serate (in buona parte buttate appresso a GIO: non usate g_file_copy_async() !!!) e nello spazio di meno di 1000 righe di C (altro argomento su cui dovro' tornare prossimamente) ho ottenuto una interfaccia a parer mio soddisfacente, minimale e proprio per questo efficiente, con le immagini che scorrono ed un pannellino per configurare i channels da seguire. Per essere stabile e' stabile, e l'API pur essendo limitata permette di fare qualsiasi cosa, alla faccia di QtGraphicsView che ad ogni minor release cambia comportamento ed ha una interfaccia troppo complessa per essere fruibile rapidamente.
Come supponevo il paradigma che sta dietro a codesto strumento va un attimo compreso prima di essere utilizzato efficacemente: all'inizio si puo' restare spiazzati dinnanzi alla totale assenza di widgets complessi che implementino le varie modalita' di interazione con l'utente, ma una volta capacitatisi del fatto che qualsiasi cosa si disegni sullo schermo puo' essere spostato, ruotato, e fatto divenire un elemento che reagisce a degli eventi esterni, si comprende il segreto intrinseco del toolkit: permettere di fare di piu', con meno.
Potrei dilungarmi qui in merito ai rischi del non avere alcuna limitazione nella definizione della propria interfaccia, fatto che si presta ad essere preludio alla totale disgregazione della coerenza tra diverse applicazioni, ma per ora interrompo qui: ci sara' modo e maniera di tornare su questi argomenti quando il tutto sara' piu' radicalmente diffuso grazie all'apparente progressiva integrazione in GNOME, e ci si potra' basare su dati concreti anziche' su illazioni.
Maggiori news sulle mie avventure estive a seguire...
martedì 28 luglio 2009
RDF = Rendiamo Difficile Fare
Pubblicato da
Roberto -MadBob- Guido
alle
01:30
0
commenti
Etichette:
integration,
nepomuk,
semantics
Ci sono giorni in cui mi ricordo perche' le tecnologie semantiche non mi convincono affatto. Oggi e' uno di essi.
Dal mio reclutamento tra le fila Nepomuk e' passato del tempo, ma sinora si e' prodotto poco: qualche altra discussione in lista Xesam, mi son migrato a mano i tickets dal vecchio tracker al nuovo, e poco altro. Evidentemente tutta la fretta imposta all'inizio non esisteva affatto, ma di questo ho gia' parlato.
Ieri son stato direttamente precettato per dire la mia in merito ad una questione che potrebbe portare ad una pesante revisione nella gestione delle mail in NMO, l'ontologia destinata al trattamento dei messaggi. I ragazzi di Tracker hanno avuto la bella pensata di riportare nella struttura semantica una mappatura 1:1 delle mail, suddividendole nei vari componenti MIME di cui sono assemblate, ed adesso che sono fuori specifica gli urge che tali correzioni vengano integrate in Nepomuk per essere compatibili con Strigi; in sostanza, hanno buttato all'aria la precedente struttura che manteneva un minimo di coerenza tra tutti i tipi di messaggi contemplati nell'ontologia.
Il bello e' che neppure gli posso dar torto, in quanto il fatto di mantenere l'informazione integra della mail cosi' com'e' non e' forse da considerare vitale ma comunque importante. Dunque, come si fa?
Cio' che si evince da questa vicenda (tutt'ora in corso: ci sara' da bestemmiare per trovare non solo una soluzione che mantenga uno straccio di coerenza ma che vada bene pure a sti' fenomeni che hanno implementato la loro propria soluzione senza chiedere niente a nessuno) e' che forse forse l'idea di "etichettare" ogni genere di contenuto nel minimo dettaglio permette certo di maneggiare con piu' rapidita' e disinvoltura il dato, ma presuppone comunque una conoscenza approfondita del dato stesso. Nello scenario di cui sopra, qualora si mantenga la struttura proposta, chiunque vorra' trattare una mail dovra' essere ben cosciente di cosa e' MIME, quali sono i metadati usati per tenere le informazioni rilevanti, ed ovviamente dovra' cambiare strategia nel momento in cui vorra' reperire un messaggio di altro tipo, ad esempio un SMS. Ed evitiamo di parlare del caso in cui vorra' far convergere questi due elementi...
Il problema intrinseco, almeno nel momento in cui tali strumenti si applicano al desktop, credo sia nella eterogeneita' dei contenuti che si dovrebbero rappresentare: i files son fatti tutti a modo loro, secondo formati propri, talvolta noti e talvolta chiusi, e la loro rappresentazione richiede troppo spesso o una mappatura completa del formato stesso o una perdita: totalmente inutile se si vogliono far collassare piu' cose secondo un criterio unificato.
Ce n'e' ancora di strada da fare per rendere usabile sta' baracca.
Dal mio reclutamento tra le fila Nepomuk e' passato del tempo, ma sinora si e' prodotto poco: qualche altra discussione in lista Xesam, mi son migrato a mano i tickets dal vecchio tracker al nuovo, e poco altro. Evidentemente tutta la fretta imposta all'inizio non esisteva affatto, ma di questo ho gia' parlato.
Ieri son stato direttamente precettato per dire la mia in merito ad una questione che potrebbe portare ad una pesante revisione nella gestione delle mail in NMO, l'ontologia destinata al trattamento dei messaggi. I ragazzi di Tracker hanno avuto la bella pensata di riportare nella struttura semantica una mappatura 1:1 delle mail, suddividendole nei vari componenti MIME di cui sono assemblate, ed adesso che sono fuori specifica gli urge che tali correzioni vengano integrate in Nepomuk per essere compatibili con Strigi; in sostanza, hanno buttato all'aria la precedente struttura che manteneva un minimo di coerenza tra tutti i tipi di messaggi contemplati nell'ontologia.
Il bello e' che neppure gli posso dar torto, in quanto il fatto di mantenere l'informazione integra della mail cosi' com'e' non e' forse da considerare vitale ma comunque importante. Dunque, come si fa?
Cio' che si evince da questa vicenda (tutt'ora in corso: ci sara' da bestemmiare per trovare non solo una soluzione che mantenga uno straccio di coerenza ma che vada bene pure a sti' fenomeni che hanno implementato la loro propria soluzione senza chiedere niente a nessuno) e' che forse forse l'idea di "etichettare" ogni genere di contenuto nel minimo dettaglio permette certo di maneggiare con piu' rapidita' e disinvoltura il dato, ma presuppone comunque una conoscenza approfondita del dato stesso. Nello scenario di cui sopra, qualora si mantenga la struttura proposta, chiunque vorra' trattare una mail dovra' essere ben cosciente di cosa e' MIME, quali sono i metadati usati per tenere le informazioni rilevanti, ed ovviamente dovra' cambiare strategia nel momento in cui vorra' reperire un messaggio di altro tipo, ad esempio un SMS. Ed evitiamo di parlare del caso in cui vorra' far convergere questi due elementi...
Il problema intrinseco, almeno nel momento in cui tali strumenti si applicano al desktop, credo sia nella eterogeneita' dei contenuti che si dovrebbero rappresentare: i files son fatti tutti a modo loro, secondo formati propri, talvolta noti e talvolta chiusi, e la loro rappresentazione richiede troppo spesso o una mappatura completa del formato stesso o una perdita: totalmente inutile se si vogliono far collassare piu' cose secondo un criterio unificato.
Ce n'e' ancora di strada da fare per rendere usabile sta' baracca.
domenica 26 luglio 2009
opengnomedesktop.org
Pubblicato da
Roberto -MadBob- Guido
alle
01:42
0
commenti
Etichette:
code,
development,
integration,
social,
web
Finalmente son riuscito a mettere online questa roba: opengnomedesktop.org e' disponibile per tutti coloro alla ricerca di qualche nuovo tema con cui personalizzare il proprio ambiente Gnome, e possono navigarne una ricca selezione (presa da gnome-look.org) valutandoli per mezzo di thumbnails simili, per non dire uguali, a quelle comunemente disponibili nel pannello "Appearance" del sistema. Allo stato attuale solo i temi GTK+2 e quelli per Metacity sono trattati, prossimamente potrei aggiungere anche quelli per il mouse, i fonts e le icone.
Quanto ora online e' da considerare a malapena un proof-of-concept, ampiamente suscettibile a prossime migliorie: il demone di sync con gnome-look.org va perfezionato per non limitarsi a fetchare gli ultimi contenuti ma per allinearsi con altri dettagli di quanto gia' assimilato, va implementata l'interfaccia Open Collaboration Service per permettere l'accesso programmatico alle risorse, devo trovare un modo furbo per eseguire la generazione delle preview (gia' che per problemi tecnici non posso eseguirla in batch direttamente sul server), va introdotto uno straccio di sistema di news per il sito... Insomma, non sono manco all'inizio.
Ma ho comunque immesso il progetto tra le proposte per il gia' piu' volte citato Social Desktop Contest, anche al fine di raccogliere un po' di feedback, ed un poco alla volta entro nell'ottica di presentare un giorno il pacchetto completo direttamente al team Gnome per l'inclusione nella piattaforma: la libreria Glib per l'accesso ai provider OCS ce l'ho, l'applicazione web che raccoglie i contenuti in modo coerente anche, mi manca un prototipo di client dedicato che ricalchi appunto il layout del pannello Appearance ma tratti il materiale online anziche' quello installato localmente e dovrei avere piu' o meno tutto.
Gia' da qualche tempo in Gnome si sente la necessita' di una piu' stretta integrazione col web, nella prossima release 2.28 saranno inclusi diversi componenti mirati in tal senso, e mi piacerebbe provare a cavalcare l'entusiasmo per spingere anche l'integrazione con OCS: sorvolando sul problema odierno dell'unicita' del fornitore (solo la rete OpenDesktop e' al momento erogatrice di risorse per mezzo del protocollo) considero tale strumento assai importante per coinvolgere con maggior profitto all'interno della community free persone che pur non sapendo nulla di programmazione possono dare il loro contributo, almeno in termini di materiale ludico con cui abbellire il desktop.
La strada per il dominio del mondo passa anche per qualche simpatica icona...
Quanto ora online e' da considerare a malapena un proof-of-concept, ampiamente suscettibile a prossime migliorie: il demone di sync con gnome-look.org va perfezionato per non limitarsi a fetchare gli ultimi contenuti ma per allinearsi con altri dettagli di quanto gia' assimilato, va implementata l'interfaccia Open Collaboration Service per permettere l'accesso programmatico alle risorse, devo trovare un modo furbo per eseguire la generazione delle preview (gia' che per problemi tecnici non posso eseguirla in batch direttamente sul server), va introdotto uno straccio di sistema di news per il sito... Insomma, non sono manco all'inizio.
Ma ho comunque immesso il progetto tra le proposte per il gia' piu' volte citato Social Desktop Contest, anche al fine di raccogliere un po' di feedback, ed un poco alla volta entro nell'ottica di presentare un giorno il pacchetto completo direttamente al team Gnome per l'inclusione nella piattaforma: la libreria Glib per l'accesso ai provider OCS ce l'ho, l'applicazione web che raccoglie i contenuti in modo coerente anche, mi manca un prototipo di client dedicato che ricalchi appunto il layout del pannello Appearance ma tratti il materiale online anziche' quello installato localmente e dovrei avere piu' o meno tutto.
Gia' da qualche tempo in Gnome si sente la necessita' di una piu' stretta integrazione col web, nella prossima release 2.28 saranno inclusi diversi componenti mirati in tal senso, e mi piacerebbe provare a cavalcare l'entusiasmo per spingere anche l'integrazione con OCS: sorvolando sul problema odierno dell'unicita' del fornitore (solo la rete OpenDesktop e' al momento erogatrice di risorse per mezzo del protocollo) considero tale strumento assai importante per coinvolgere con maggior profitto all'interno della community free persone che pur non sapendo nulla di programmazione possono dare il loro contributo, almeno in termini di materiale ludico con cui abbellire il desktop.
La strada per il dominio del mondo passa anche per qualche simpatica icona...
venerdì 17 luglio 2009
Mail, XML e Thumbs
Pubblicato da
Roberto -MadBob- Guido
alle
22:52
0
commenti
Etichette:
code,
contest,
development,
influenze,
lobotomy,
SubConsciousDaemon
Questo post non e' per un commento o una divagazione specifica e mirata, ma semplicemente per aggiornare i miei lettori sulle attivita' correnti. Del resto, se non ho tempo di bloggare e' perche' ho altro da fare.
Per conto di Itsme negli ultimi giorni ho dovuto "smontare" Evolution, il client mail di Gnome, e trarne una sorta di mail client batch, che non interagisca con l'utente per mezzo di una interfaccia grafica ma popoli il database del backend con le mail in ingresso ed intercetti le nuove mail create (sempre sul database) per spedirle. Al di la' del gusto intrinseco di codesta attivita' (andare a mettere il naso in qualche progetto open ha sempre il suo fascino...) la cosa interessante e' che, con qualche opportuno ritocco qua e la', codesto componente potrebbe divenire il primo pezzo concreto del SubConsciousDaemon di Lobotomy: il funzionamento e' esattamente quello che contavo di realizzare appunto per il mio ambiente, dunque tanto vale riutilizzare questo codice che sara' comunque prossimamente rilasciato in licenza free.
Sempre in merito a Lobotomy: sembra quasi incredibile, ma son tornato a lavorarci. Negli scorsi giorni ho ripreso in mano il dialetto XML per i Thoughts, per accertarmi del fatto che vengano coperti tutti i casi piu' comuni e che comunque non esistano limiti intrinsechi alla definizione di pressoche' tutte le "applicazioni" utili. A breve, terminati gli altri task gia' in corso (e descritti sotto) conto finalmente di iniziare Synapse, ovvero l'interprete del suddetto XML e piu' in generale il gestore dei templates.
Altrove sto ultimando l'opera sul generatore di thumbs dai contenuti di Gnome-Look.org: nonostante abbia avuto un po' da magheggiare per ottenere il risultato desiderato, in quanto i links dei temi da cui trarre la preview non sono fatti per essere trattati programmaticamente e negli archivi compressi i files sono organizzati spesso in modi totalmente arbitrari, e nonostante le limitazioni tecniche sul VPS su cui andra' poi a girare il sito (non son riuscito ad eseguire X.org non essendoci giustamente una scheda grafica, e senza X.org non si puo' lanciare il codice di generazione batch delle thumbs), il demone preposto al download ed all'elaborazione dei temi GTK e Metacity e' pressoche' pronto ed ora debbo solo rifinire l'interfaccia web del sistema. Una volta completata anche quella sottoporro' pure questo progetto al Social Desktop Contest, che ad un mese dalla chiusura conta un solo partecipante (me!) e da cui posso dunque sperare in una proclamazione: sembra la sceneggiatura di uno spot del Gratta e Vinci, quelli della serie "Ti piace vincere facile?", ma se cio' comporta l'acquisizione da parte mia di un netbook non me ne lamento.
Insomma, c'e' sempre qualcosa su cui lavorare...
Per conto di Itsme negli ultimi giorni ho dovuto "smontare" Evolution, il client mail di Gnome, e trarne una sorta di mail client batch, che non interagisca con l'utente per mezzo di una interfaccia grafica ma popoli il database del backend con le mail in ingresso ed intercetti le nuove mail create (sempre sul database) per spedirle. Al di la' del gusto intrinseco di codesta attivita' (andare a mettere il naso in qualche progetto open ha sempre il suo fascino...) la cosa interessante e' che, con qualche opportuno ritocco qua e la', codesto componente potrebbe divenire il primo pezzo concreto del SubConsciousDaemon di Lobotomy: il funzionamento e' esattamente quello che contavo di realizzare appunto per il mio ambiente, dunque tanto vale riutilizzare questo codice che sara' comunque prossimamente rilasciato in licenza free.
Sempre in merito a Lobotomy: sembra quasi incredibile, ma son tornato a lavorarci. Negli scorsi giorni ho ripreso in mano il dialetto XML per i Thoughts, per accertarmi del fatto che vengano coperti tutti i casi piu' comuni e che comunque non esistano limiti intrinsechi alla definizione di pressoche' tutte le "applicazioni" utili. A breve, terminati gli altri task gia' in corso (e descritti sotto) conto finalmente di iniziare Synapse, ovvero l'interprete del suddetto XML e piu' in generale il gestore dei templates.
Altrove sto ultimando l'opera sul generatore di thumbs dai contenuti di Gnome-Look.org: nonostante abbia avuto un po' da magheggiare per ottenere il risultato desiderato, in quanto i links dei temi da cui trarre la preview non sono fatti per essere trattati programmaticamente e negli archivi compressi i files sono organizzati spesso in modi totalmente arbitrari, e nonostante le limitazioni tecniche sul VPS su cui andra' poi a girare il sito (non son riuscito ad eseguire X.org non essendoci giustamente una scheda grafica, e senza X.org non si puo' lanciare il codice di generazione batch delle thumbs), il demone preposto al download ed all'elaborazione dei temi GTK e Metacity e' pressoche' pronto ed ora debbo solo rifinire l'interfaccia web del sistema. Una volta completata anche quella sottoporro' pure questo progetto al Social Desktop Contest, che ad un mese dalla chiusura conta un solo partecipante (me!) e da cui posso dunque sperare in una proclamazione: sembra la sceneggiatura di uno spot del Gratta e Vinci, quelli della serie "Ti piace vincere facile?", ma se cio' comporta l'acquisizione da parte mia di un netbook non me ne lamento.
Insomma, c'e' sempre qualcosa su cui lavorare...
lunedì 29 giugno 2009
libopengdesktop
Come precedentemente annunciato negli ultimi giorni mi son messo ad implementare una piccola libreria che permette l'accesso ai servizi web compatibili Open Collaboration Services con un wrapper Glib, e dunque facilmente usabile in Gnome e XFCE. Sebbene certamente non ancora all'altezza di attica, ovvero l'implementazione per KDE, credo che libopengdesktop sia gia' usabile per piccoli applicativi senza pretese: mancano ancora le funzioni che permettono di comunicare con il server remoto in modalita' asincrona, indispensabili per l'utilizzo in una qualsiasi applicazione grafica che interagisca direttamente con l'utente, ma gia' il GTK+ Theme Thumbnailer menzionato nel precedente post sarebbe realizzabile senza eccessivo sforzo.
Per quanto questa faccenda del Social Desktop Contest in parte non mi torni, in quanto sembra abbastanza una bufala architettata a tavolino per l'interesse di pochi (e come al solito approfondiro' queste tematiche sull'altro mio blog), ha comunque stimolato i miei neuroni gia' peraltro eccitati dal bioritmo estivo, ed ora mi trovo con una quantita' di idee grandi e piccine che potrebbero essere presentate o comunque messe in opera per il puro gusto di far qualcosa di utile. Poiche' gia' so che non riusciro' mai a realizzarle tutte le condivido nella speranza che qualcun'altro si prenda carico di qualcuna di esse: se cio' dovesse succedere, lasciate un commento a questo pezzo cosi' evitiamo di lavorarci in due...
Per quanto questa faccenda del Social Desktop Contest in parte non mi torni, in quanto sembra abbastanza una bufala architettata a tavolino per l'interesse di pochi (e come al solito approfondiro' queste tematiche sull'altro mio blog), ha comunque stimolato i miei neuroni gia' peraltro eccitati dal bioritmo estivo, ed ora mi trovo con una quantita' di idee grandi e piccine che potrebbero essere presentate o comunque messe in opera per il puro gusto di far qualcosa di utile. Poiche' gia' so che non riusciro' mai a realizzarle tutte le condivido nella speranza che qualcun'altro si prenda carico di qualcuna di esse: se cio' dovesse succedere, lasciate un commento a questo pezzo cosi' evitiamo di lavorarci in due...
- una implementazione AGPLv3 della piattaforma Open Collaboration Services (per quanto incredibile lo stesso OpenDesktop, riferimento stesso della specifica, sembrerebbe costruito su una piattaforma web closed source... Andiam bene...). Questo di per se dovrebbe essere il progetto che andrebbe ad includere anche il GTK+ Theme Thumbnailer, ed il primo su cui mi mettero' a lavorare non appena avro' un poco di tempo
- un driver Gwibber per le funzionalita' di microblogging incluse nel formato
- un driver Evolution per gestire i messaggi privati tra gli utenti
- un'altro driver Evolution (o comunque un convertitore iCal) per importare nel calendar le informazioni relative agli eventi che vengono pubblicati
- una qualche forma di integrazione con GeoClue per la gestione ad alto livello delle informazioni geografiche (magari una estensione di libopengdesktop?)
- una applicazioncina Facebook che condivida su tale popoloso network le attivita' svolte su una piattaforma Open Desktop
venerdì 19 giugno 2009
GTK+ Theme Thumbnailer
Giusto il tempo di commentare il Social Desktop Contest, che in quattro e quattr'otto contro ogni piu' rosea aspettativa son riuscito ad implementare (sebbene sia da rifinire) la prima proposta che avevo in mente. Non si tratta di nulla di eclatante, per la carita', ma la trovo comunque una opzione nella sua semplicita' originale ed utile.
Partiamo da un presupposto: i contenuti solitamente accessibili sui vari siti della rete OpenDesktop hanno il grosso problema di non essere programmaticamente gestibili. Bellissimi i Nautilus Scripts, o le applicazioncine su kde-apps, ma fintantoche' la loro installazione ed il loro utilizzo richiedono un intervento consapevole dell'utente (che deve decomprimere l'archivio e leggere il README per sapere di volta in volta quali files prendere e dove spostarli), e non esiste dunque alcuna forma di pacchettizzazione, non si puo' pensare ad uno strumento che faciliti la propagazione di codesti micro-applicativi con una modalita' di interazione fruibile dagli utilizzatori domestici (ovvero: "Clicca qui e faccio tutto io"). Dello stesso difetto, o meglio di una sua variante, soffrono i materiali meno impegnativi e destinati all'abbellimento grafico del proprio desktop: splendide le sfilze infinite di GTK+ engines e decorazioni per le finestre di Metacity, ma se ognuna di esse e' rappresentata da uno screenshot preso alla meno peggio dal rispettivo sviluppatore/artista ed in situazioni sempre diverse e' difficile poterne valutare la gradevolezza e tocca comunque scaricare ed installare prima di accorgersi che la personalizzazione sulla propria postazione di lavoro non piace.
Proprio a questa seconda problematica e' rivolto il mio modestissimo progetto: un servizio web che wrappi alcuni dei contenuti di gnome-look generando automaticamente le preview dei vari temi disponibili sempre secondo lo stesso layout di widgets.
Mettendo il naso nel codice di gnome-control-center, ovvero l'applicativo che in Gnome permette la selezione di vari parametri di visualizzazione, si scopre che le thumbnails sono generate dinamicamente partendo sempre dalla stessa configurazione di widgets (si vedono rispettivamente un pulsante, una checkbox ed un radiobutton) si' da affiancare in modo equo e confrontabile le differenti opzioni; da li', e' stato un attimo isolare le funzioni che provvedono a tale generazione e realizzare un eseguibile standalone capace di produrre una JPEG a partire da un qualunque tema, da poi fornire in accompagnamento ai contenuti esposti da un ipotetico server che come detto funga da provider per un altrettanto ipotetico pannello Gnome arricchito da un tasto che permetta di pescare da esso (come gia' succede nel pannello dei wallpapers di KDE).
Paradossalmente adesso arriva la parte piu' noiosa e complessa, ovvero quella di provvedere ad una libreria C (e magari GObject oriented...) che wrappi l'API REST descritta dalla specifica Open Collaboration e permetta di comunicare col server senza doversi ogni volta parsare l'XML, e gia' da solo questo task meriterebbe di essere contemplato come entry a se' stante per il Contest. Ad ogni modo credo che l'ostacolo piu' imponente, ovvero la creazione di preview coerenti, sia stato abbondantemente superato, e da adesso la strada e' in discesa: non so se una trovata cosi' modesta possa realmente avere uno spazio all'interno della competizione internazionale (e anche se lo fosse, l'Italia e' storicamente tagliata fuori dei concorsi a premi che si svolgono nel resto del mondo...), ma ribadisco l'intento puramente materialistico dell'opera.
Ogni tanto un qualche simpatico hack per passar la serata e' d'uopo...
Partiamo da un presupposto: i contenuti solitamente accessibili sui vari siti della rete OpenDesktop hanno il grosso problema di non essere programmaticamente gestibili. Bellissimi i Nautilus Scripts, o le applicazioncine su kde-apps, ma fintantoche' la loro installazione ed il loro utilizzo richiedono un intervento consapevole dell'utente (che deve decomprimere l'archivio e leggere il README per sapere di volta in volta quali files prendere e dove spostarli), e non esiste dunque alcuna forma di pacchettizzazione, non si puo' pensare ad uno strumento che faciliti la propagazione di codesti micro-applicativi con una modalita' di interazione fruibile dagli utilizzatori domestici (ovvero: "Clicca qui e faccio tutto io"). Dello stesso difetto, o meglio di una sua variante, soffrono i materiali meno impegnativi e destinati all'abbellimento grafico del proprio desktop: splendide le sfilze infinite di GTK+ engines e decorazioni per le finestre di Metacity, ma se ognuna di esse e' rappresentata da uno screenshot preso alla meno peggio dal rispettivo sviluppatore/artista ed in situazioni sempre diverse e' difficile poterne valutare la gradevolezza e tocca comunque scaricare ed installare prima di accorgersi che la personalizzazione sulla propria postazione di lavoro non piace.
Proprio a questa seconda problematica e' rivolto il mio modestissimo progetto: un servizio web che wrappi alcuni dei contenuti di gnome-look generando automaticamente le preview dei vari temi disponibili sempre secondo lo stesso layout di widgets.
Mettendo il naso nel codice di gnome-control-center, ovvero l'applicativo che in Gnome permette la selezione di vari parametri di visualizzazione, si scopre che le thumbnails sono generate dinamicamente partendo sempre dalla stessa configurazione di widgets (si vedono rispettivamente un pulsante, una checkbox ed un radiobutton) si' da affiancare in modo equo e confrontabile le differenti opzioni; da li', e' stato un attimo isolare le funzioni che provvedono a tale generazione e realizzare un eseguibile standalone capace di produrre una JPEG a partire da un qualunque tema, da poi fornire in accompagnamento ai contenuti esposti da un ipotetico server che come detto funga da provider per un altrettanto ipotetico pannello Gnome arricchito da un tasto che permetta di pescare da esso (come gia' succede nel pannello dei wallpapers di KDE).
{kind=link}
{kind=link}
Paradossalmente adesso arriva la parte piu' noiosa e complessa, ovvero quella di provvedere ad una libreria C (e magari GObject oriented...) che wrappi l'API REST descritta dalla specifica Open Collaboration e permetta di comunicare col server senza doversi ogni volta parsare l'XML, e gia' da solo questo task meriterebbe di essere contemplato come entry a se' stante per il Contest. Ad ogni modo credo che l'ostacolo piu' imponente, ovvero la creazione di preview coerenti, sia stato abbondantemente superato, e da adesso la strada e' in discesa: non so se una trovata cosi' modesta possa realmente avere uno spazio all'interno della competizione internazionale (e anche se lo fosse, l'Italia e' storicamente tagliata fuori dei concorsi a premi che si svolgono nel resto del mondo...), ma ribadisco l'intento puramente materialistico dell'opera.
Ogni tanto un qualche simpatico hack per passar la serata e' d'uopo...
giovedì 18 giugno 2009
L'Unione fa... il Desktop
Sembra che la community di sviluppo freesoftware si sia svegliata tutta d'un colpo per concentrare almeno una parte delle risorse in tema di design ed usabilita' dei prodotti open: dopo il recentemente commentato contest di Mozilla (per cui ammetto di aver abbandonato il proposito di partecipare in modo serio, avrei voluto mettere insieme un piccolo prototipo ma le incombenze sono sempre troppe...) nel giro di pochi giorni sono spuntati fuori il progetto "One Hundred Paper Cuts" ed il "Social Desktop Contest".
Il primo si tratta di uno "sprint" che punta ad individuare e correggere 100 piccoli bugs all'interno dell'interfaccia di Ubuntu (notoriamente: Gnome) entro un breve periodo di tempo, puntando l'attenzione soprattutto sulle piccole ma fastidiose incoerenze che possono peggiorare la user expericence dell'utente novizio ma d'altro canto possono essere sistemate con poco sforzo. La lista delle segnalazioni e' ricca, e posso sperare che i developers coinvolti non chiuderanno la baracca arrivati al centesimo ticket chiuso ma lavoreranno comunque per sistemare il sistemabile. Considero l'iniziativa ottima, purtroppo non ha molto senso che a condurla sia un'unico vendor (Ubuntu, appunto, considerando che alla fine il codice corretto e' quello di Gnome) ma e' un modo efficace per coinvolgere l'utenza domestica, piu' sensibile ad imprecisioni che potrebbero passare inosservate ad un esperto, e perfezionare alcuni dei dettagli che fanno la differenza tra un prodotto buono ed uno eccelso.
Di tutt'altro genere e' il contest indetto da Social Desktop (che in realta' e' solo un'altro nome per OpenDesktop...), che mira a stimolare la produzione di qualche applicativo nuovo e creativo che sfrutti la specifica Open Collaboration Services by Freedesktop.org per l'integrazione del desktop Linux con funzionalita' di social networking. Sebbene in lavorazione da qualche tempo il formato per il recupero, la condivisione e la valutazione di contenuti addizionali per i PC casalinghi (wallpapers, icone, piccole utility...) non ha mai preso particolarmente piede, forse anche perche' l'unico fornitore degno di nome del servizio e' appunto OpenDesktop (quelli, per capirci, che mandano avanti gnome-look e kde-look), e solo ultimamente l'implementazione di una parte dei servizi all'interno di KDE4 (come al solito annunciata con le fanfare) ha riportato l'attenzione sul tema. Io credo che alla specifica manchi ancora molto per essere davvero utilizzabile e non rappresentare solo un guscio di fuffa "duepuntozero", ma tornero' prossimamente su tali considerazioni: al momento sto accarezzando l'idea di assemblare qualcosa per suddetto contest, sperando di produrre qualcosa di piu' che non per la sopra menzionata competizione Mozilla, e quando opportuno esporro' un approfondimento.
Insomma, la morale del post e': basta un poco di ingegno per architettare iniziative ampiamente fruibili dalla community (e non solo dagli sviluppatori, che paradossalmente sono sempre piu' una minoranza), in grado di condurre a ricchi risultati con un impiego modesto di risorse. Mi auguro di continuare a vedere spesso questo genere di imprese da parte dei team piu' grandi e con maggiore risonanza mediatica.
Il primo si tratta di uno "sprint" che punta ad individuare e correggere 100 piccoli bugs all'interno dell'interfaccia di Ubuntu (notoriamente: Gnome) entro un breve periodo di tempo, puntando l'attenzione soprattutto sulle piccole ma fastidiose incoerenze che possono peggiorare la user expericence dell'utente novizio ma d'altro canto possono essere sistemate con poco sforzo. La lista delle segnalazioni e' ricca, e posso sperare che i developers coinvolti non chiuderanno la baracca arrivati al centesimo ticket chiuso ma lavoreranno comunque per sistemare il sistemabile. Considero l'iniziativa ottima, purtroppo non ha molto senso che a condurla sia un'unico vendor (Ubuntu, appunto, considerando che alla fine il codice corretto e' quello di Gnome) ma e' un modo efficace per coinvolgere l'utenza domestica, piu' sensibile ad imprecisioni che potrebbero passare inosservate ad un esperto, e perfezionare alcuni dei dettagli che fanno la differenza tra un prodotto buono ed uno eccelso.
Di tutt'altro genere e' il contest indetto da Social Desktop (che in realta' e' solo un'altro nome per OpenDesktop...), che mira a stimolare la produzione di qualche applicativo nuovo e creativo che sfrutti la specifica Open Collaboration Services by Freedesktop.org per l'integrazione del desktop Linux con funzionalita' di social networking. Sebbene in lavorazione da qualche tempo il formato per il recupero, la condivisione e la valutazione di contenuti addizionali per i PC casalinghi (wallpapers, icone, piccole utility...) non ha mai preso particolarmente piede, forse anche perche' l'unico fornitore degno di nome del servizio e' appunto OpenDesktop (quelli, per capirci, che mandano avanti gnome-look e kde-look), e solo ultimamente l'implementazione di una parte dei servizi all'interno di KDE4 (come al solito annunciata con le fanfare) ha riportato l'attenzione sul tema. Io credo che alla specifica manchi ancora molto per essere davvero utilizzabile e non rappresentare solo un guscio di fuffa "duepuntozero", ma tornero' prossimamente su tali considerazioni: al momento sto accarezzando l'idea di assemblare qualcosa per suddetto contest, sperando di produrre qualcosa di piu' che non per la sopra menzionata competizione Mozilla, e quando opportuno esporro' un approfondimento.
Insomma, la morale del post e': basta un poco di ingegno per architettare iniziative ampiamente fruibili dalla community (e non solo dagli sviluppatori, che paradossalmente sono sempre piu' una minoranza), in grado di condurre a ricchi risultati con un impiego modesto di risorse. Mi auguro di continuare a vedere spesso questo genere di imprese da parte dei team piu' grandi e con maggiore risonanza mediatica.
lunedì 8 giugno 2009
CustomCaptionPanel per GWT
Come ogni altro framework, anche il Google Web Toolkit (gia' piu' volte menzionato in questo blog) inizia a dare soddisfazioni quando lo si riesce ad usare decentemente. Oggi, ispirato da un colpo di genio (o meglio di memoria...), questo articolo e la consultazione del codice interno di alcune classi, ho implementato ed incluso in GASdotto questa semplice classe che permette di utilizzare un fieldset come Cristo comanda, ovvero con le label.
Grazie a questo piccolo espediente e' possibile generare una gerarchia DOM che formatta i contenuti senza fare uso di tabelle (non tanto per questioni di accessibilita', comunque compromessa trattandosi di roba compilata in Javascript, ma interessante in termini di elementi che il layout engine del browser si trova a dover manipolare), e riccamente configurabile per mezzo di CSS come nell'esempio incluso nel codice della classe sopra linkata.
Il risultato ottenuto e' esteticamente assai gradevole, ed ovviamente ancora migliorabile se solo fossi capace di spremere CSS in modo esaustivo, e sebbene ancora non perfetto (il CaptionPanel cosi' taroccato non permette di installare listeners sugli elementi trattati, per intercettare ad esempio il focus, e non ho ancora capito come aggirare...) spero che questo pezzetto di codice torni utile a qualcuno.
Grazie a questo piccolo espediente e' possibile generare una gerarchia DOM che formatta i contenuti senza fare uso di tabelle (non tanto per questioni di accessibilita', comunque compromessa trattandosi di roba compilata in Javascript, ma interessante in termini di elementi che il layout engine del browser si trova a dover manipolare), e riccamente configurabile per mezzo di CSS come nell'esempio incluso nel codice della classe sopra linkata.
Il risultato ottenuto e' esteticamente assai gradevole, ed ovviamente ancora migliorabile se solo fossi capace di spremere CSS in modo esaustivo, e sebbene ancora non perfetto (il CaptionPanel cosi' taroccato non permette di installare listeners sugli elementi trattati, per intercettare ad esempio il focus, e non ho ancora capito come aggirare...) spero che questo pezzetto di codice torni utile a qualcuno.
venerdì 5 giugno 2009
Tanto va il Bob al Largo...
Pubblicato da
Roberto -MadBob- Guido
alle
23:59
0
commenti
Etichette:
influenze,
nepomuk,
semantics,
xesam
Ci sono situazioni della vita in cui non si puo' non restare affascinati dinnanzi agli inaspettati risultati che una caotica serie di eventi puo' produrre: ho piu' volte conosciuto per puro caso persone che a distanza di tempo ed in intricate circostanze si sono rilevate indispensabili, ho vissuto esperienze incredibilmente belle o incredibilmente brutte che mi hanno permesso di accedere ad altri scenari ancora piu' estremi, e mi sono trovato in condizioni paradossali a seguito di non meglio descrivibili catene di cause ed effetti.
Questa e' una di quelle situazioni.
Io, eterno scettico nei confronti del desktop semantico, e acceso critico nei confronti di organizzazioni ufficiali e para-corporate nel contesto dello sviluppo free, sono da oggi co-maintainer di un componente di Nepomuk.
Non sto qui a spiegare il come ed il perche' di tale evoluzione, e se lo facessi comunque pubblicherei il resoconto sul mio blog piu' "politicamente attivo" a causa dei risvolti che la vicenda ha e continuera' ad avere, ma basti qui menzionare il fatto che nel prossimo periodo avro' modo di approfondire persino piu' del dovuto il tema delle tecnologie semantiche ed i loro risvolti.
L'incarico si prospetta tutt'altro che semplice, considerando che in fin dei conti la definizione di una ontologia non e' null'altro che un confronto dialettico tra due o piu' persone che vogliono imporre la propria visione soggettiva delle cose senza poter fondare la discussione su aspetti tecnici e misurabili, lunghissimi flames sono gia' stati prodotti nei confronti di innumerevoli dettagli che avrebbero dovuto essere inclusi, esclusi o modificati ed il mio compito sara' quello di moderarli. Se a cio' aggiungiamo l'hype che Nepomuk detiene, avendo galvanizzato una buona fetta della community a seguito dell'implementazione (comunque a tutt'ora in corso d'opera) in KDE, ed il fatto che dovro' confrontarmi con personaggi di un certo spessore e di una certa esperienza (nella pagina sopra linkata appaiono, oltre al mio, i nomi di almeno un paio di maintainer di Tracker ed il co-maintainer di Xesam), la sfida si fa ancora piu' ardita.
Ridendo e scherzando gia' so che passero' il weekend a documentarmi sui tickets gia' in passato aperti sul componente a me assegnato e sulle modifiche che qualcuno ha arbitrariamente apportato senza pero' passare per la validazione da parte della community, preparandomi mentalmente e fisicamente al ciclo di sviluppo che iniziera' nel prossimo periodo a causa della chiusura dell'originario progetto Nepomuk sponsorizzato dall'Unione Europea ed alla migrazione della baracca sotto l'egida della fantomatica OSCAF, ambigua organizzazione il cui compito non e' ancora chiaro e per la quale indirettamente mi son trovato in codesta situazione.
Vabbe', guardiamo il lato positivo: con tutte le mail di insulti internazionali che dovro' mandare, magari il mio inglese scritto migliorera'...
Questa e' una di quelle situazioni.
Io, eterno scettico nei confronti del desktop semantico, e acceso critico nei confronti di organizzazioni ufficiali e para-corporate nel contesto dello sviluppo free, sono da oggi co-maintainer di un componente di Nepomuk.
Non sto qui a spiegare il come ed il perche' di tale evoluzione, e se lo facessi comunque pubblicherei il resoconto sul mio blog piu' "politicamente attivo" a causa dei risvolti che la vicenda ha e continuera' ad avere, ma basti qui menzionare il fatto che nel prossimo periodo avro' modo di approfondire persino piu' del dovuto il tema delle tecnologie semantiche ed i loro risvolti.
L'incarico si prospetta tutt'altro che semplice, considerando che in fin dei conti la definizione di una ontologia non e' null'altro che un confronto dialettico tra due o piu' persone che vogliono imporre la propria visione soggettiva delle cose senza poter fondare la discussione su aspetti tecnici e misurabili, lunghissimi flames sono gia' stati prodotti nei confronti di innumerevoli dettagli che avrebbero dovuto essere inclusi, esclusi o modificati ed il mio compito sara' quello di moderarli. Se a cio' aggiungiamo l'hype che Nepomuk detiene, avendo galvanizzato una buona fetta della community a seguito dell'implementazione (comunque a tutt'ora in corso d'opera) in KDE, ed il fatto che dovro' confrontarmi con personaggi di un certo spessore e di una certa esperienza (nella pagina sopra linkata appaiono, oltre al mio, i nomi di almeno un paio di maintainer di Tracker ed il co-maintainer di Xesam), la sfida si fa ancora piu' ardita.
Ridendo e scherzando gia' so che passero' il weekend a documentarmi sui tickets gia' in passato aperti sul componente a me assegnato e sulle modifiche che qualcuno ha arbitrariamente apportato senza pero' passare per la validazione da parte della community, preparandomi mentalmente e fisicamente al ciclo di sviluppo che iniziera' nel prossimo periodo a causa della chiusura dell'originario progetto Nepomuk sponsorizzato dall'Unione Europea ed alla migrazione della baracca sotto l'egida della fantomatica OSCAF, ambigua organizzazione il cui compito non e' ancora chiaro e per la quale indirettamente mi son trovato in codesta situazione.
Vabbe', guardiamo il lato positivo: con tutte le mail di insulti internazionali che dovro' mandare, magari il mio inglese scritto migliorera'...
martedì 2 giugno 2009
Mozilla Design Challenge, parte 1
Essendomi perso il contest per il re-design di OpenOffice, qualche giorno fa' ho deciso di partecipare a quello indetto da Mozilla per l'ideazione di una alternativa alle classiche tabs per la navigazione di piu' pagine contemporaneamente in Firefox.
Si parte dal presupposto che (cito testualmente) "oggi avere 20 o piu' sessioni parallele e' cosa comune", e nell'ottica di fornire un nuovo strumento di gestione della propria vita digitale si sta cercando un mezzo piu' efficiente che non le comodissime ma comunque limitanti tabs tradizionalmente poste al di sopra delle pagine.
Ieri sera ho confezionato una prima proposta, anche se ammetto apertamente che sia piuttosto banale: come si vede in questi mockups (e nell'orribile video che riporto anche qui sotto) ho piazzato le tabs in una sidebar, ispirandomi all'oramai diffuso utilizzo di monitor widescreen che offrono tanto spazio orizzontale, anche se tale presupposto non vale per gli altrettanto diffusi netbooks e tale approccio contempli comunque una semplicissima reimplementazione dello stesso identico concetto gia' esistente.
se non che si e' trattato di un (neppure tanto riuscito) esercizio di stile.
Ma come gia' detto, questa si tratta solo di una prima proposta: un'altra ne ho nel cassetto, in buona parte ispirata ed adattata dal meccanismo di navigazione dei templates pensato per Synapse. Certamente un "template" (nell'accezione assunta all'interno di Lobotomy) e' cosa diversa da una pagina web, dunque qualche revisione va apportata, ma provero' quanto prima a confezionare anche quest'altra proposal da inviare al team Mozilla.
Apprezzo immensamente lo sforzo profuso da Mozilla nella ricerca in campo di usabilita' e HCI, settore in cui tipicamente il software open deficita: il fatto di trattare l'interfaccia della propria applicazione con la stessa cura con cui si tratta il codice e' sintomo di consapevolezza nei confronti del "mercato" e dell'utenza, ed evidenzia l'intenzione di elevare la qualita' del software secondo canoni troppo spesso tralasciati e considerati secondari.
Con i miei modestissimi interventi non conto di lasciare un segno particolare presso il team Mozilla, ma il solo fatto di fomentare la creativita' di collaboratori freelance avvezzi al design ed all'usabilita' permette di avere una ricaduta su tutto il panorama e di generare concepts che potranno essere facilmente riutilizzati in altri progetti. Ben vengano dunque iniziative di questo genere, che dovrebbero anzi essere intraprese da tutti i progetti open di un certo spessore.
Si parte dal presupposto che (cito testualmente) "oggi avere 20 o piu' sessioni parallele e' cosa comune", e nell'ottica di fornire un nuovo strumento di gestione della propria vita digitale si sta cercando un mezzo piu' efficiente che non le comodissime ma comunque limitanti tabs tradizionalmente poste al di sopra delle pagine.
Ieri sera ho confezionato una prima proposta, anche se ammetto apertamente che sia piuttosto banale: come si vede in questi mockups (e nell'orribile video che riporto anche qui sotto) ho piazzato le tabs in una sidebar, ispirandomi all'oramai diffuso utilizzo di monitor widescreen che offrono tanto spazio orizzontale, anche se tale presupposto non vale per gli altrettanto diffusi netbooks e tale approccio contempli comunque una semplicissima reimplementazione dello stesso identico concetto gia' esistente.
se non che si e' trattato di un (neppure tanto riuscito) esercizio di stile.
Ma come gia' detto, questa si tratta solo di una prima proposta: un'altra ne ho nel cassetto, in buona parte ispirata ed adattata dal meccanismo di navigazione dei templates pensato per Synapse. Certamente un "template" (nell'accezione assunta all'interno di Lobotomy) e' cosa diversa da una pagina web, dunque qualche revisione va apportata, ma provero' quanto prima a confezionare anche quest'altra proposal da inviare al team Mozilla.
Apprezzo immensamente lo sforzo profuso da Mozilla nella ricerca in campo di usabilita' e HCI, settore in cui tipicamente il software open deficita: il fatto di trattare l'interfaccia della propria applicazione con la stessa cura con cui si tratta il codice e' sintomo di consapevolezza nei confronti del "mercato" e dell'utenza, ed evidenzia l'intenzione di elevare la qualita' del software secondo canoni troppo spesso tralasciati e considerati secondari.
Con i miei modestissimi interventi non conto di lasciare un segno particolare presso il team Mozilla, ma il solo fatto di fomentare la creativita' di collaboratori freelance avvezzi al design ed all'usabilita' permette di avere una ricaduta su tutto il panorama e di generare concepts che potranno essere facilmente riutilizzati in altri progetti. Ben vengano dunque iniziative di questo genere, che dovrebbero anzi essere intraprese da tutti i progetti open di un certo spessore.
lunedì 1 giugno 2009
Fuori Onda
Pubblicato da
Roberto -MadBob- Guido
alle
15:19
0
commenti
Etichette:
integration,
news,
social,
web
Giacche' il web sembra in fermento per l'ultima trovata Google, inutile non volerne discutere anche su questo blog.
In poche parole: Wave e' un tool per far convergere diverse forse di discussione, tra cui instant messaging e commenti sui blogs, e di editing collaborativo. Sara' che gli esempi forniti nel corso della presentazione ufficiale del prodotto (di cui e' disponibile il video nella homepage del progetto) sono abbastanza banali ed ingenui, ma al contrario della maggior parte della blogosfera a me non pare nulla di particolarmente eccitante.
Per la carita', una API che permetta di gestire in modo complesso gli stream di discussioni e commenti e' piu' che benvenuta, e gia' pregusto il momento in cui la includero' in GASdotto per arricchire le possibilita' di interazione degli utenti, ma in fin dei conti di strumenti per l'editing collaborativo ne esistono gia' a quintalate (sia web che desktop), e neanche si contano i mezzi con cui due o piu' persone possono comunicare in modo piu' o meno sincrono.
Probabilmente l'aspetto piu' innovativo del prodotto sta nella formalizzazione di un protocollo per l'aggregazione di contenuti, che garantisce la possibilita' di implementazioni inedite e maggiori spazi per l'integrazione di servizi offerti da diversi providers (nonche' di applicativi di interfaccia magari un po' piu' usabili che non il client Wave proposto da Google stessa, che mi pare tutto fuorche' immediato e semplice da utilizzare), ma come sempre c'e' da vedere se davvero tale arnese verra' portato laddove ce ne sarebbe bisogno, ovvero social networks e piattaforme di (micro)blogging, oppure se ancora una volta le divergenze del libero mercato concorrenziale imporranno limiti alla radicazione della specifica.
Piu' in generale, il mio giudizio nei confronti di questo genere di strumenti di carattere "social" e' sempre abbastanza critico: bellissima la possibilita' di condividere commenti, informazioni, notizie ed opinioni, ma se alla fine tutto questo popo' di tecnologia viene usato per far divulgare le foto delle vacanze non si ottiene nulla di piu' che non la versione globalizzata e 2.0 della "serata a casa degli amici a vedere le diapositive della settimana al mare". Quel che mancano non sono i mezzi, ma i contenuti, o comunque un qualche criterio che faccia emergere i dati realmente utili per la conduzione dei processi di decision making.
Gia' mi sono altrove espresso favorevolmente nei confronti dei nuovi media e dei canali di comunicazione "peer2peer" offerti dalla moderna Internet, ma giunti a questo punto ci si aspetterebbe da un colosso come Google (o da chiunque altro con un forte potenziale innovativo) qualcosa di piu' che non un servizio di instant messaging potenziato.
Forse la salvezza arrivera' dal semantic web, ma i tempi sembrano tutt'altro che maturi. Forse la salvezza arrivera' da Lobotomy, o da Itsme, o da qualche altro progetto che porta l'aggregazione dell'informazione al centro del modello di interazione, ma l'attesa sembra essere tutt'altro che breve. E nel frattempo aumenta la mole di informazione da filtrare a mano, e troppo spesso succede di perdersi i pezzi per la strada.
In poche parole: Wave e' un tool per far convergere diverse forse di discussione, tra cui instant messaging e commenti sui blogs, e di editing collaborativo. Sara' che gli esempi forniti nel corso della presentazione ufficiale del prodotto (di cui e' disponibile il video nella homepage del progetto) sono abbastanza banali ed ingenui, ma al contrario della maggior parte della blogosfera a me non pare nulla di particolarmente eccitante.
Per la carita', una API che permetta di gestire in modo complesso gli stream di discussioni e commenti e' piu' che benvenuta, e gia' pregusto il momento in cui la includero' in GASdotto per arricchire le possibilita' di interazione degli utenti, ma in fin dei conti di strumenti per l'editing collaborativo ne esistono gia' a quintalate (sia web che desktop), e neanche si contano i mezzi con cui due o piu' persone possono comunicare in modo piu' o meno sincrono.
Probabilmente l'aspetto piu' innovativo del prodotto sta nella formalizzazione di un protocollo per l'aggregazione di contenuti, che garantisce la possibilita' di implementazioni inedite e maggiori spazi per l'integrazione di servizi offerti da diversi providers (nonche' di applicativi di interfaccia magari un po' piu' usabili che non il client Wave proposto da Google stessa, che mi pare tutto fuorche' immediato e semplice da utilizzare), ma come sempre c'e' da vedere se davvero tale arnese verra' portato laddove ce ne sarebbe bisogno, ovvero social networks e piattaforme di (micro)blogging, oppure se ancora una volta le divergenze del libero mercato concorrenziale imporranno limiti alla radicazione della specifica.
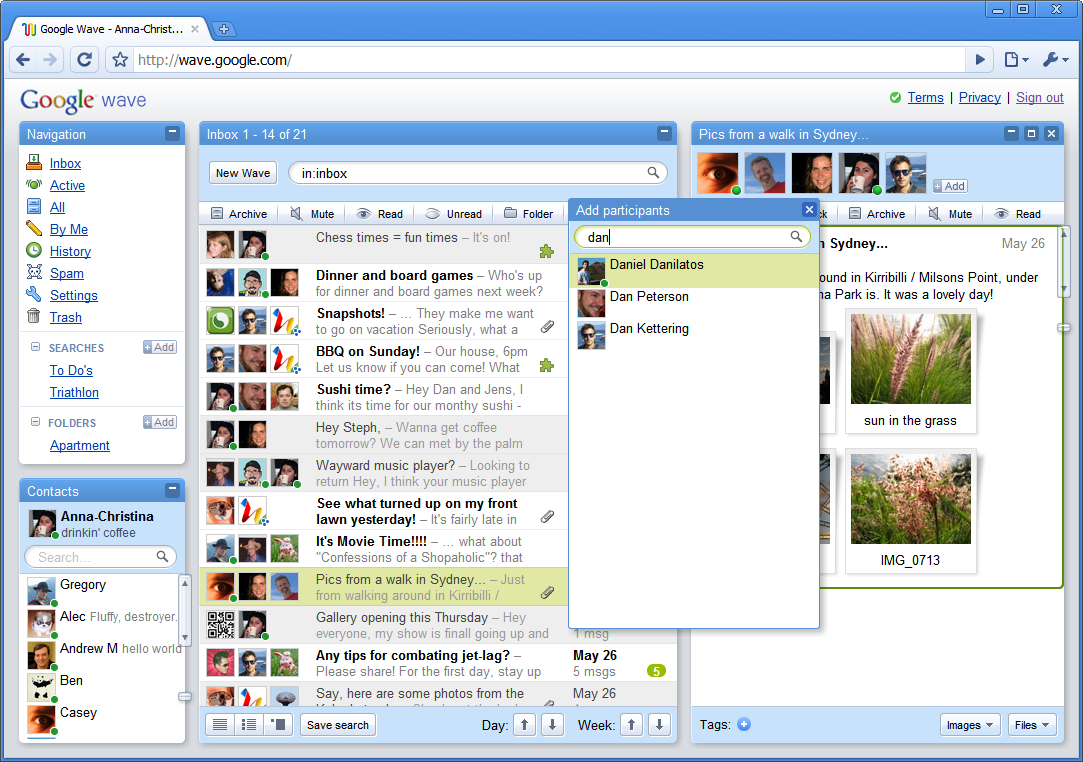{kind=link}
Piu' in generale, il mio giudizio nei confronti di questo genere di strumenti di carattere "social" e' sempre abbastanza critico: bellissima la possibilita' di condividere commenti, informazioni, notizie ed opinioni, ma se alla fine tutto questo popo' di tecnologia viene usato per far divulgare le foto delle vacanze non si ottiene nulla di piu' che non la versione globalizzata e 2.0 della "serata a casa degli amici a vedere le diapositive della settimana al mare". Quel che mancano non sono i mezzi, ma i contenuti, o comunque un qualche criterio che faccia emergere i dati realmente utili per la conduzione dei processi di decision making.
Gia' mi sono altrove espresso favorevolmente nei confronti dei nuovi media e dei canali di comunicazione "peer2peer" offerti dalla moderna Internet, ma giunti a questo punto ci si aspetterebbe da un colosso come Google (o da chiunque altro con un forte potenziale innovativo) qualcosa di piu' che non un servizio di instant messaging potenziato.
Forse la salvezza arrivera' dal semantic web, ma i tempi sembrano tutt'altro che maturi. Forse la salvezza arrivera' da Lobotomy, o da Itsme, o da qualche altro progetto che porta l'aggregazione dell'informazione al centro del modello di interazione, ma l'attesa sembra essere tutt'altro che breve. E nel frattempo aumenta la mole di informazione da filtrare a mano, e troppo spesso succede di perdersi i pezzi per la strada.
lunedì 18 maggio 2009
Strutture Algoritmiche
Un post gustosamente tecnico, inevitabile epilogo di una giornata interamente passata a programmare manipolando una infinita' di strutture dati.
Gia' da tempo ho constatato l'enorme gap che esiste tra le strutture dati comunemente conosciute, usate ed implementate nelle piu' svariate librerie, e l'architettura di un qualsiasi sistema la cui complessita' e' maggiore del classico hello world: laddove, seguendo i canoni della programmazione strutturata, si isolano (e stratificano...) le routines in modo da essere quanto piu' generiche possibili, alla lunga molto facilmente si arriva a replicare gli stessi dati in piu' e piu' posti semplicemente perche' in diversi posti si necessita di un diverso ordinamento, di una diversa gerarchia o di un diverso tipo di elemento che possa essere passato alle funzioni esposte da un diverso framework. E la pigrizia, prima virtu' di ogni developer, induce a ridurre, se non eliminare del tutto, l'implementazione di nuove strutture dati ad hoc da adottare caso per caso, ma ad adoperare due o tre o quattro istanze delle strutture normalmente fornite da qualsiasi libreria di utility e gestite su piu' piani differenti.
Un esempio concreto, fresco fresco e tratto dall'esperienza di oggi: ho usato una GHashTable per mantenere i riferimenti ad alcuni oggetti presi da un'altro componente e da restituire ad un'altro. Ma tali componenti ai due estremi del flusso sono fatti per "ragionare" secondo parametri diversi di cotali oggetti, mentre l'hash table permette di indicizzarli secondo un criterio solo. Risultato: quando le richieste arrivano da una parte l'accesso e' immediato, quando arrivano dall'altro devo convertire in una GList allocata sul momento, iterare, e liberare la struttura temporanea. Quanto sarebbe piu' efficiente il tutto se realizzassi una hash table personalizzata con due (o meglio ancora, un numero arbitrario di) indici distinti, o meglio ancora perfezionassi la gia' esistente GRelation (che non sembra godere di molta attenzione da parte del team Glib)? Molto, tutto sta nell'avere tempo di farlo.
E ancora: come detto gli oggetti sono presi da una parte e passati dall'altra, ma questo comporta una duplicazione delle stesse informazioni. Informazioni che sono rappresentate in modi completamente diversi, ma che vanno ordinate piu' e piu' volte, iterate piu' e piu' volte, sincronizzate piu' e piu' volte... Quanto sarebbe piu' rapido e performante l'insieme se si provvedesse ad una qualche forma di struttura condivisa mantenuta allineata una sola volta per tutte? Molto, ma richiederebbe non poco sforzo per la realizzazione di qualcosa di stabile date le condizioni di concorrenza.
E' probabile (anzi pressoche' certo) che la' fuori esistano centinaia di concetti nuovi, magari gia' anche implementati e testati e debuggati, ma che non sono ancora stati "scoperti" ed introdotti nei toolkit piu' popolari, i quali spesso magari neppure implementano le gia' ben note strutture piu' di nicchia e raffinate.
Nel contesto del Progetto Lobotomy iniziai ad esplorare, insieme ad altri spunti per esotiche strutture dati tra cui una ispirata dalle architetture multi-core, il concetto di "extension", ovvero estensioni dei tipi di dato fondamentali con altri oggetti che li descrivessero in modi diversi e ad essi direttamente agganciati al fine di avere un'unica lista in cui aggiungere e rimuovere elementi ed in cui cercare secondo un criterio ed ottenere immediatamente la diversa rappresentazione (ad esempio: cercare un HyppoVFSItem ed avere subito il relativo all'interno della GtkIconView senza dover iterare altrove), ma tanto per cambiare non ebbi modo di approfondire ulteriormente le potenzialita' del concept e non ottenni alcunche' di effettivamente usabile.
Un giorno o l'altro dovro' tornarci, su questo e su altre ricerche. Per intanto mi accontento delle mie hash table tradotte in liste...
Gia' da tempo ho constatato l'enorme gap che esiste tra le strutture dati comunemente conosciute, usate ed implementate nelle piu' svariate librerie, e l'architettura di un qualsiasi sistema la cui complessita' e' maggiore del classico hello world: laddove, seguendo i canoni della programmazione strutturata, si isolano (e stratificano...) le routines in modo da essere quanto piu' generiche possibili, alla lunga molto facilmente si arriva a replicare gli stessi dati in piu' e piu' posti semplicemente perche' in diversi posti si necessita di un diverso ordinamento, di una diversa gerarchia o di un diverso tipo di elemento che possa essere passato alle funzioni esposte da un diverso framework. E la pigrizia, prima virtu' di ogni developer, induce a ridurre, se non eliminare del tutto, l'implementazione di nuove strutture dati ad hoc da adottare caso per caso, ma ad adoperare due o tre o quattro istanze delle strutture normalmente fornite da qualsiasi libreria di utility e gestite su piu' piani differenti.
Un esempio concreto, fresco fresco e tratto dall'esperienza di oggi: ho usato una GHashTable per mantenere i riferimenti ad alcuni oggetti presi da un'altro componente e da restituire ad un'altro. Ma tali componenti ai due estremi del flusso sono fatti per "ragionare" secondo parametri diversi di cotali oggetti, mentre l'hash table permette di indicizzarli secondo un criterio solo. Risultato: quando le richieste arrivano da una parte l'accesso e' immediato, quando arrivano dall'altro devo convertire in una GList allocata sul momento, iterare, e liberare la struttura temporanea. Quanto sarebbe piu' efficiente il tutto se realizzassi una hash table personalizzata con due (o meglio ancora, un numero arbitrario di) indici distinti, o meglio ancora perfezionassi la gia' esistente GRelation (che non sembra godere di molta attenzione da parte del team Glib)? Molto, tutto sta nell'avere tempo di farlo.
E ancora: come detto gli oggetti sono presi da una parte e passati dall'altra, ma questo comporta una duplicazione delle stesse informazioni. Informazioni che sono rappresentate in modi completamente diversi, ma che vanno ordinate piu' e piu' volte, iterate piu' e piu' volte, sincronizzate piu' e piu' volte... Quanto sarebbe piu' rapido e performante l'insieme se si provvedesse ad una qualche forma di struttura condivisa mantenuta allineata una sola volta per tutte? Molto, ma richiederebbe non poco sforzo per la realizzazione di qualcosa di stabile date le condizioni di concorrenza.
E' probabile (anzi pressoche' certo) che la' fuori esistano centinaia di concetti nuovi, magari gia' anche implementati e testati e debuggati, ma che non sono ancora stati "scoperti" ed introdotti nei toolkit piu' popolari, i quali spesso magari neppure implementano le gia' ben note strutture piu' di nicchia e raffinate.
Nel contesto del Progetto Lobotomy iniziai ad esplorare, insieme ad altri spunti per esotiche strutture dati tra cui una ispirata dalle architetture multi-core, il concetto di "extension", ovvero estensioni dei tipi di dato fondamentali con altri oggetti che li descrivessero in modi diversi e ad essi direttamente agganciati al fine di avere un'unica lista in cui aggiungere e rimuovere elementi ed in cui cercare secondo un criterio ed ottenere immediatamente la diversa rappresentazione (ad esempio: cercare un HyppoVFSItem ed avere subito il relativo all'interno della GtkIconView senza dover iterare altrove), ma tanto per cambiare non ebbi modo di approfondire ulteriormente le potenzialita' del concept e non ottenni alcunche' di effettivamente usabile.
Un giorno o l'altro dovro' tornarci, su questo e su altre ricerche. Per intanto mi accontento delle mie hash table tradotte in liste...
Iscriviti a:
Post (Atom)