Un post gustosamente tecnico, inevitabile epilogo di una giornata interamente passata a programmare manipolando una infinita' di strutture dati.
Gia' da tempo ho constatato l'enorme gap che esiste tra le strutture dati comunemente conosciute, usate ed implementate nelle piu' svariate librerie, e l'architettura di un qualsiasi sistema la cui complessita' e' maggiore del classico hello world: laddove, seguendo i canoni della programmazione strutturata, si isolano (e stratificano...) le routines in modo da essere quanto piu' generiche possibili, alla lunga molto facilmente si arriva a replicare gli stessi dati in piu' e piu' posti semplicemente perche' in diversi posti si necessita di un diverso ordinamento, di una diversa gerarchia o di un diverso tipo di elemento che possa essere passato alle funzioni esposte da un diverso framework. E la pigrizia, prima virtu' di ogni developer, induce a ridurre, se non eliminare del tutto, l'implementazione di nuove strutture dati ad hoc da adottare caso per caso, ma ad adoperare due o tre o quattro istanze delle strutture normalmente fornite da qualsiasi libreria di utility e gestite su piu' piani differenti.
Un esempio concreto, fresco fresco e tratto dall'esperienza di oggi: ho usato una GHashTable per mantenere i riferimenti ad alcuni oggetti presi da un'altro componente e da restituire ad un'altro. Ma tali componenti ai due estremi del flusso sono fatti per "ragionare" secondo parametri diversi di cotali oggetti, mentre l'hash table permette di indicizzarli secondo un criterio solo. Risultato: quando le richieste arrivano da una parte l'accesso e' immediato, quando arrivano dall'altro devo convertire in una GList allocata sul momento, iterare, e liberare la struttura temporanea. Quanto sarebbe piu' efficiente il tutto se realizzassi una hash table personalizzata con due (o meglio ancora, un numero arbitrario di) indici distinti, o meglio ancora perfezionassi la gia' esistente GRelation (che non sembra godere di molta attenzione da parte del team Glib)? Molto, tutto sta nell'avere tempo di farlo.
E ancora: come detto gli oggetti sono presi da una parte e passati dall'altra, ma questo comporta una duplicazione delle stesse informazioni. Informazioni che sono rappresentate in modi completamente diversi, ma che vanno ordinate piu' e piu' volte, iterate piu' e piu' volte, sincronizzate piu' e piu' volte... Quanto sarebbe piu' rapido e performante l'insieme se si provvedesse ad una qualche forma di struttura condivisa mantenuta allineata una sola volta per tutte? Molto, ma richiederebbe non poco sforzo per la realizzazione di qualcosa di stabile date le condizioni di concorrenza.
E' probabile (anzi pressoche' certo) che la' fuori esistano centinaia di concetti nuovi, magari gia' anche implementati e testati e debuggati, ma che non sono ancora stati "scoperti" ed introdotti nei toolkit piu' popolari, i quali spesso magari neppure implementano le gia' ben note strutture piu' di nicchia e raffinate.
Nel contesto del Progetto Lobotomy iniziai ad esplorare, insieme ad altri spunti per esotiche strutture dati tra cui una ispirata dalle architetture multi-core, il concetto di "extension", ovvero estensioni dei tipi di dato fondamentali con altri oggetti che li descrivessero in modi diversi e ad essi direttamente agganciati al fine di avere un'unica lista in cui aggiungere e rimuovere elementi ed in cui cercare secondo un criterio ed ottenere immediatamente la diversa rappresentazione (ad esempio: cercare un HyppoVFSItem ed avere subito il relativo all'interno della GtkIconView senza dover iterare altrove), ma tanto per cambiare non ebbi modo di approfondire ulteriormente le potenzialita' del concept e non ottenni alcunche' di effettivamente usabile.
Un giorno o l'altro dovro' tornarci, su questo e su altre ricerche. Per intanto mi accontento delle mie hash table tradotte in liste...
Pensieri e parole su HCI, home computing, tecnologie desktop e sul Progetto Lobotomy
lunedì 18 maggio 2009
domenica 10 maggio 2009
Social Software
Pubblicato da
Roberto -MadBob- Guido
alle
19:03
0
commenti
Etichette:
influenze,
integration,
social,
web
Nella 2020 FLOSS Roadmap, il documento (assolutamente non ufficiale, ma comunque fonte di ispirazione) che descrive i punti chiave in cui sviluppare e promuovere il software libero nei prossimi anni affinche' possa viralmente innestarsi sul panorama IT precedendo le controparti proprietarie (ed alla fine conquistare il mondo!!! Mhuahahaha!!!), uno spazietto e' dedicato al "Social Software".
Mettendo le mani avanti in merito al significato che tale buzzword dovrebbe avere, e che nella mia interpretazione differisce dalla definizione fornita da Wikipedia, il termine mi ispira un concetto che val la pena di esplorare ed implementare, o quantomeno di uniformare a partire dalle gia' esistenti sporadiche incarnazioni. Tale concetto e' quello di applicare una dimensione "social" (nell'accezione di "social networking") alla distribuzione del software, integrando servizi collaterali come il rating e l'aggiunta di commenti per ogni pacchetto installabile per mezzo del package manager, si' da arricchire quasi passivamente la documentazione relativa alle applicazioni accessibili dagli utenti.
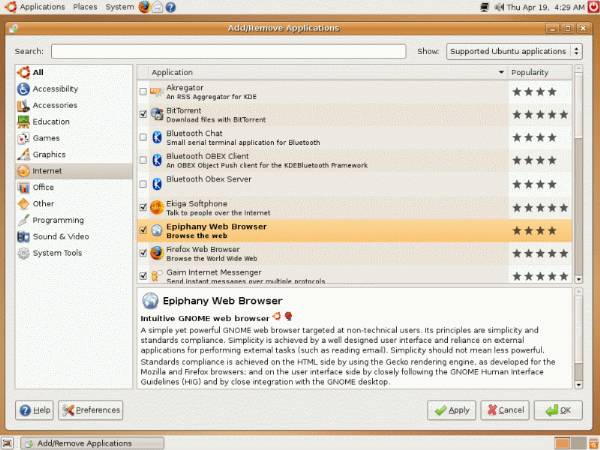
L'idea e' tutt'altro che nuova, viene gia' marginalmente applicata in Ubuntu (che rappresenta la popolarita' delle applicazioni con delle stelline di merito) ed in Entropy (il package manager di Sabayon, progetto che ho modo di seguire abbastanza da vicino e che non nascondo abbia in buona parte influenzato la mia posizione sui temi qui trattati), ma trattandosi di applicazioni indipendenti, non compatibili e limitate risultano solo parzialmente utili ai fini dello sfruttamento intensivo dell'idea. Per questo motivo ho gia' provveduto a gettare il sasso nello stagno di PackageKit, progetto FreeDesktop che punta all'astrazione del package management sulle piu' disparate distribuzioni ed esporre questa funzionalita' in modo che sia programmaticamente raggiungibile anche da applicativi che non siano il package manager in senso stretto, ed attendo qualche commento in merito.
In un futuro il proposito potrebbe essere esteso anche a forme di contenuti "user generated" piu' significativi che non gli sterili commenti, come ad esempio una maggiore interazione in caso di errore dell'applicazione (e conseguente bug report) e l'avanzamento di idee e proposte per nuove features e migliorie: anche in questo caso esistono gia' parziali implementazioni dai singoli vendor (ad esempio Firefox provvede a presentare il dialog di bug reporting in caso di errore, mentre il team Ubuntu gestisce un suo proprio collettore di suggerimenti online), e provvedere una soluzione unica, riusabile e facilmente gestibile (per evitare gli ovvi doppioni che scaturirebbero da una adozione di massa del sistema, da individuare nel modo piu' automatico possibile) permetterebbe di incrementare notevolmente le possibilita' di produrre software di gran qualita'.
Il sofware libero siamo noi, dunque tanto vale fornire strumenti efficaci per lo svolgimento del proprio compito.
Mettendo le mani avanti in merito al significato che tale buzzword dovrebbe avere, e che nella mia interpretazione differisce dalla definizione fornita da Wikipedia, il termine mi ispira un concetto che val la pena di esplorare ed implementare, o quantomeno di uniformare a partire dalle gia' esistenti sporadiche incarnazioni. Tale concetto e' quello di applicare una dimensione "social" (nell'accezione di "social networking") alla distribuzione del software, integrando servizi collaterali come il rating e l'aggiunta di commenti per ogni pacchetto installabile per mezzo del package manager, si' da arricchire quasi passivamente la documentazione relativa alle applicazioni accessibili dagli utenti.
L'idea e' tutt'altro che nuova, viene gia' marginalmente applicata in Ubuntu (che rappresenta la popolarita' delle applicazioni con delle stelline di merito) ed in Entropy (il package manager di Sabayon, progetto che ho modo di seguire abbastanza da vicino e che non nascondo abbia in buona parte influenzato la mia posizione sui temi qui trattati), ma trattandosi di applicazioni indipendenti, non compatibili e limitate risultano solo parzialmente utili ai fini dello sfruttamento intensivo dell'idea. Per questo motivo ho gia' provveduto a gettare il sasso nello stagno di PackageKit, progetto FreeDesktop che punta all'astrazione del package management sulle piu' disparate distribuzioni ed esporre questa funzionalita' in modo che sia programmaticamente raggiungibile anche da applicativi che non siano il package manager in senso stretto, ed attendo qualche commento in merito.
{kind=link}
In un futuro il proposito potrebbe essere esteso anche a forme di contenuti "user generated" piu' significativi che non gli sterili commenti, come ad esempio una maggiore interazione in caso di errore dell'applicazione (e conseguente bug report) e l'avanzamento di idee e proposte per nuove features e migliorie: anche in questo caso esistono gia' parziali implementazioni dai singoli vendor (ad esempio Firefox provvede a presentare il dialog di bug reporting in caso di errore, mentre il team Ubuntu gestisce un suo proprio collettore di suggerimenti online), e provvedere una soluzione unica, riusabile e facilmente gestibile (per evitare gli ovvi doppioni che scaturirebbero da una adozione di massa del sistema, da individuare nel modo piu' automatico possibile) permetterebbe di incrementare notevolmente le possibilita' di produrre software di gran qualita'.
{kind=link}
Il sofware libero siamo noi, dunque tanto vale fornire strumenti efficaci per lo svolgimento del proprio compito.
venerdì 1 maggio 2009
"Lobotam"?
Pubblicato da
Roberto -MadBob- Guido
alle
18:29
3
commenti
Etichette:
development,
Hyppocampus,
influenze,
lobotomy,
semantics,
xesam
Negli ultimi tempi, per motivi legati in qualche modo al lavoro, mi sono documentato in modo abbastanza approfondito su Xesam, ovvero il protocollo FreeDesktop che intende unificare l'accesso ai dati piu' o meno semantici raccolti dai vari indexers quali Tracker, Beagle e compagnia cantante. E sebbene un anno fa', in occasione del primo approccio col progetto stesso, espressi una critica alla modalita' di utilizzo del formato, dopo aver rovistato il wiki in lungo ed in largo ed aver constatato l'incredibile frammentazione esistente nel mondo open in merito al tema del desktop semantico mi sono cosi' convinto della necessita' di questa opera che non solo mi sono iscritto alla mailing list ed ho preso (modestissima) parte all'atto finale che prelude al rilascio della versione 1.0 della specifica (oramai imminente) ma mi sto anche persuadendo che, almeno per ora, potrei utilizzare tale strumento all'interno di Lobotomy, sostituendo il mio personale storage relazionale Hyppocampus con un indexer canonico acceduto appunto grazie al protocollo standard.
Questo porterebbe all'impossibilita' di implementare alcune delle features avanzate che avevo elaborato, come il versioning dei singoli metadati e l'utilizzo ortogonale di informazioni cronologiche, ma certamente il fatto di non dovermi occupare personalmente di una componente grossa ed impegnativa come l'estrattore, indicizzatore e fornitore dei metadati mi permetterebbe finalmente di ottenere qualcosa di concreto nell'ambito del mio oramai anzianissimo ma poco produttivo progetto. E si puo' anche immaginare che in questo modo Lobotomy, inteso come ambiente operativo, potra' anche piu' facilmente essere adoperato, valutato e testato all'interno di un desktop environment canonico, ed essere utile a qualcuno per gestire i propri dati senza necessariamente dipendere dall'approccio distruttivo e radicale che presupporrebbe l'utilizzo esclusivo della mia esotica interfaccia.
Conto di concentrarmi prossimamente sui task prettamente presentativi del sistema, nella fattispecie su Synapse, e faro' in modo di wrappare l'interfaccia Xesam in modo che sia facilmente sostituibile il giorno in cui disporro' di uno storage relazionale fatto a modo mio.
Lobotomy + Xesam = Lobotam!
Questo porterebbe all'impossibilita' di implementare alcune delle features avanzate che avevo elaborato, come il versioning dei singoli metadati e l'utilizzo ortogonale di informazioni cronologiche, ma certamente il fatto di non dovermi occupare personalmente di una componente grossa ed impegnativa come l'estrattore, indicizzatore e fornitore dei metadati mi permetterebbe finalmente di ottenere qualcosa di concreto nell'ambito del mio oramai anzianissimo ma poco produttivo progetto. E si puo' anche immaginare che in questo modo Lobotomy, inteso come ambiente operativo, potra' anche piu' facilmente essere adoperato, valutato e testato all'interno di un desktop environment canonico, ed essere utile a qualcuno per gestire i propri dati senza necessariamente dipendere dall'approccio distruttivo e radicale che presupporrebbe l'utilizzo esclusivo della mia esotica interfaccia.
Conto di concentrarmi prossimamente sui task prettamente presentativi del sistema, nella fattispecie su Synapse, e faro' in modo di wrappare l'interfaccia Xesam in modo che sia facilmente sostituibile il giorno in cui disporro' di uno storage relazionale fatto a modo mio.
Lobotomy + Xesam = Lobotam!
Iscriviti a:
Post (Atom)